
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- subplots
- Python
- interpolate
- 결측치대체
- 결측치
- countplot
- IterativeImputer
- MSE
- 보간법
- Seaborn
- stopwords
- BDA
- 누락값
- 대치법
- koNLPy
- 파이썬
- 전처리
- sklearn
- DataFrame
- 데이터프레임
- KoNLP
- value_counts
- join
- matplotlib
- Boxplot
- 불용어
- Outlier
- SimpleImputer
- 이상치
- 선형보간
Archives
- Today
- Total
ACAIT
[BDA 데분기] 7주차 - 데이터 병합 본문
데이터 병합에 대해 배운 내용을 정리해 보겠습니다.
- SQL의 join과 같은 역할. 원하는 테이블 쿼리로 추출.
- 파이썬도 동일하게 작업 가능.
- SQL은 빠르게 확인할 때, 파이썬은 환경이나 제약조건이 있어서 무겁게 데이터 다뤄야 함.
하지만 충분히 데이터 병합에 대한 스킬 향상 필요. - merge(), concat() 잘 이해하기.
- R, Python, SQL 병합 맥락 모두 같음. 하나 능숙해지면 나머지도 쉬움.
1. concat()
- 덩어리 + 덩어리.
- 데이터프레임끼리 서로 합치는 경우.
- join 조건 없는 상황에 쓰임.
- axis: 축 설정. '0 = 0행, 1열 기준.'
- ignore_index: 병합 후 인덱스 재설정.










1-1. concat 사용 case
- 시계열 인덱스 기준, 날짜 기준으로 데이터 붙이는 경우.
- 아예 다른 데이터(공통 기준 없는 경우) 병합하는 경우.
2. merge()
- join이라는 함수가 들어감.
- 공통의 컬럼(pk 개념)이 필요함.
- 공통적인 부분을 기준으로 합친다.
2-1. 주요 파라미터
- left: 첫 번째로 쓴 데이터프레임.
- right: 두 번째로 쓴 데이터프레임.(두 개 기준. 세 개 이상은 순서에 따라 정렬)
- on: join key로 사용할 컬럼.
- left_on: 왼쪽 데이터프레임에서 join key로 사용할 컬럼.
- right_on: 오른쪽 데이터프레임에서 join key로 사용할 컬럼.
- left_index: 왼쪽 데이터프레임의 join 기준 index 사용할지 여부.
- right_index: 오른쪽 데이터프레임의 join 기준 index 사용할지 여부.
- how: join 방법. default = inner.

- 조인: 대부분 하나의 테이블, 데이터프레임에서 얻을 수 없는 결과를 하나의 테이블로 만들어 다양한 데이터 분석.
2-1-1. join key가 하나인 경우

2-1-2. join key 두 개 이상인 경우



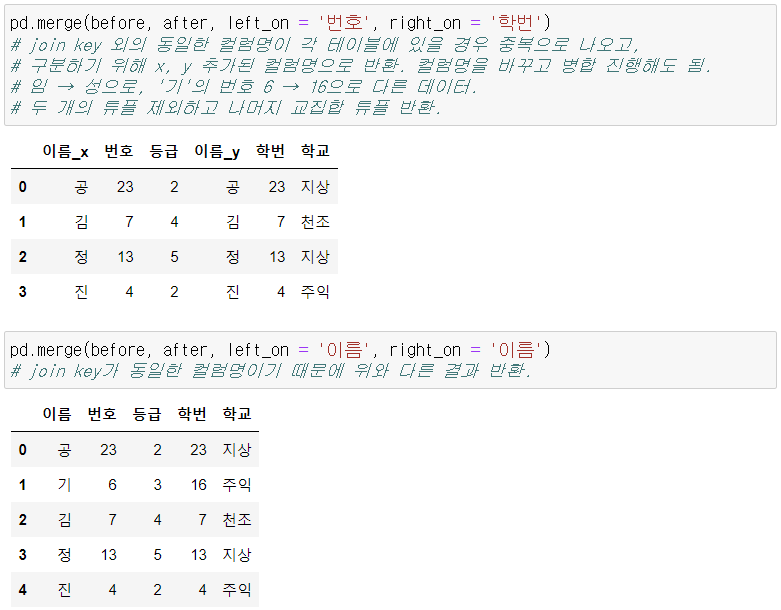
2-1-3. left_on, right_on
- 테이블별로 컬럼명이 다를 경우.
- 값은 동일하다면 해당 컬럼으로 지정해서 조인.


2-1-4. index 기준 병합
- left_index
- right_index






2-1-5. how
- 조인의 다양한 방법.
- inner: 공통 교집합 튜플만 병합.
- left: 왼쪽 데이터프레임의 join key 기준 병합.
- right: 오른쪽 데이터프레임의 join key 기준 병합.
- outer: 양쪽 데이터프레임의 join key 기준 병합.






2-1-6. 병합 오류 테스트








- 잘 병합되려면 데이터프레임 쉐입, 공통 컬럼 등 많은 고려가 필요함.
- 미리 데이터 검증할 때 위 내용들 미리 생각해 보고 진행.
3. 샘플 데이터로 실습



- 두 개씩 테이블을 병합해야 하는 상황.
- 어느 데이터프레임을 left로 둘지, inner, outer 무엇을 선택할지는 데이터베이스 설계 개념을 이해해야 한다.
- vit 데이터가 전체 메타데이터(메타스키마: 전체를 기록,관리하는 유니크한 데이터)라면 vit를 기준으로 둬야 함.
- 유니크한 값은 site 데이터로 예상되고, 현재 실습 상황에서는 inner로 진행.



'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 9주차 - 데이터 시각화, 시계열 데이터 분석 (0) | 2024.01.31 |
|---|---|
| [BDA 데분기] 8주차 - 데이터 시각화, matplotlib, seaborn (1) | 2024.01.31 |
| [BDA 데분기] 6주차 필수 과제 2 - 데이터 재구조화 (0) | 2024.01.31 |
| [BDA 데분기] 6주차 - Series, DataFrame 관련 함수 (0) | 2024.01.31 |
| [BDA 데분기] 5주차 필수 과제 - 이상치 관련 분석 (0) | 2024.01.31 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



