
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- Outlier
- 결측치대체
- IterativeImputer
- 대치법
- stopwords
- 이상치
- Python
- value_counts
- countplot
- KoNLP
- MSE
- koNLPy
- matplotlib
- 전처리
- Boxplot
- BDA
- interpolate
- 결측치
- 불용어
- SimpleImputer
- 선형보간
- 데이터프레임
- subplots
- join
- sklearn
- 누락값
- 보간법
- Seaborn
- DataFrame
- 파이썬
Archives
- Today
- Total
ACAIT
[BDA 데분기] 11주차 - 데이터 전처리 본문
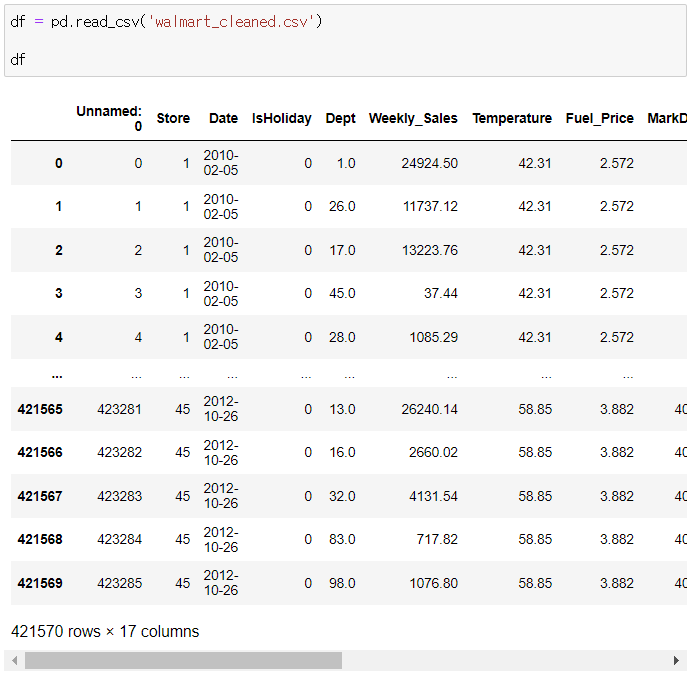
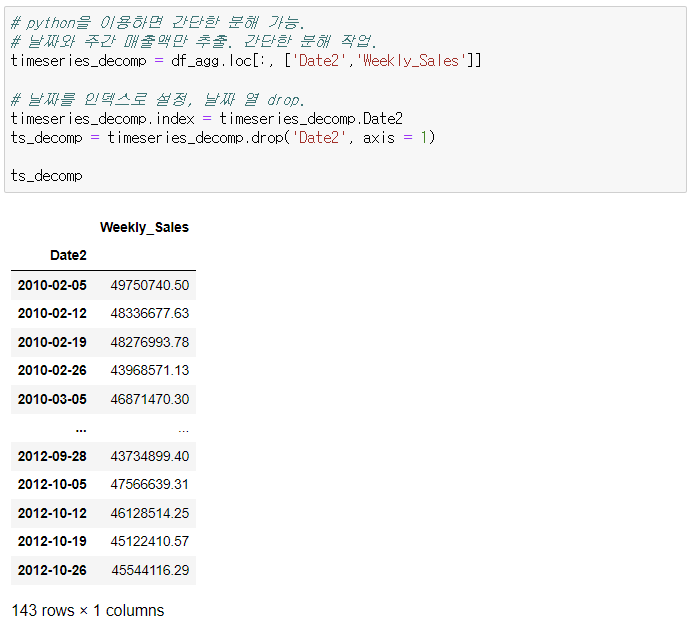
0. 마트 월매출 데이터 전처리 과정
- 주별 집계 데이터. 테이블 생성 필요.
- datetime으로 데이터 유형 변경.
- 시계열 데이터는 dt.year, dt.month 등으로 데이터 일부 추출 가능.
# apply(): 데이터 변환시키는 함수.
- df.apply(함수, axis = 0 or 1) (default = 0)



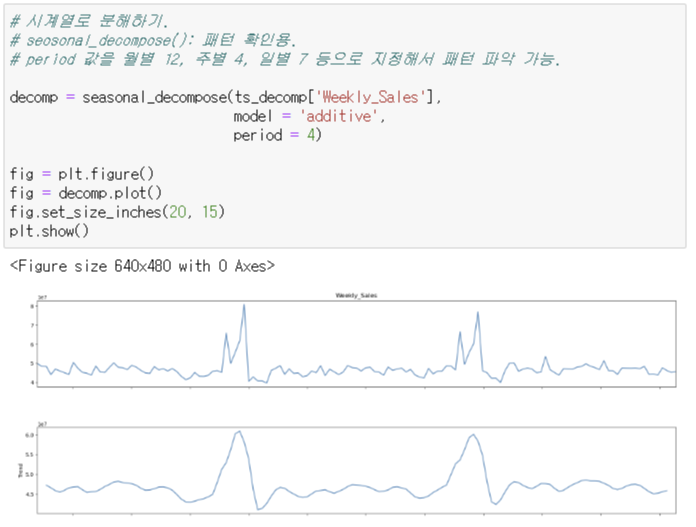

ACF, PACF 함수 그래프 그리기

- 1 다음에 값이 바로 급격히 떨어지는 것을 보아 주기로 봤을 때 1주차 전에 영향이 있는 것으로 보인다.
- 그래프에 나온 것처럼 연말에 영향력이 있다는 것을 확인할 수 있다.
1. 회귀분석을 통한 예측
- 다항회귀 개념의 예측. 변수를 여럿 사용할 수 있다.


- Nan값을 다 0으로 대체해서 가중치가 잘못 잡혀 좋지 않은 결과가 나옴.
- 다중회귀 진행인데 스케일링 진행 않고 0으로 대체한 것이 문제.
- 결론: 선형회귀 할 때 0으로 잡으면 문제 발생한다는 것.
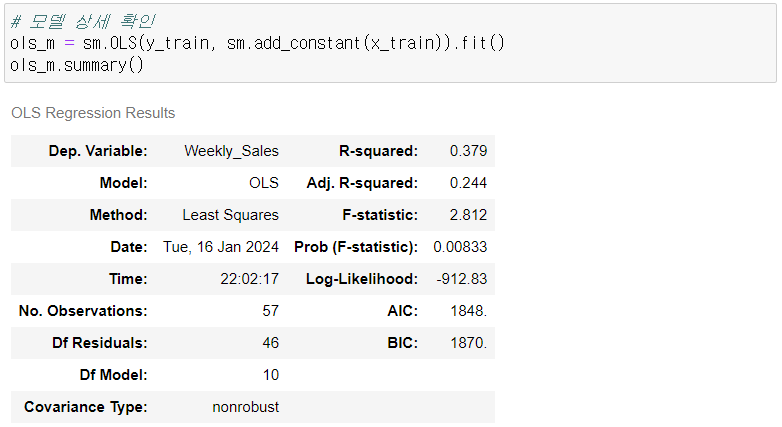
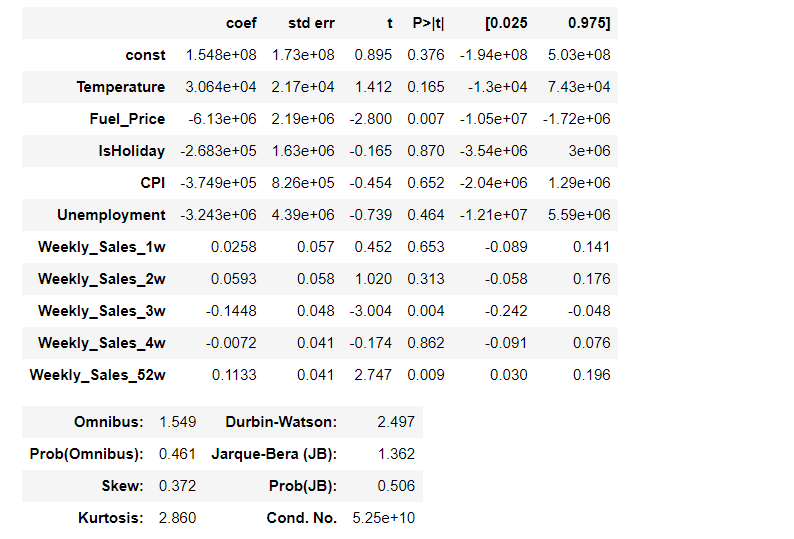
# Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 5.25e+10. This might indicate that there are
strong multicollinearity or other numerical problems.
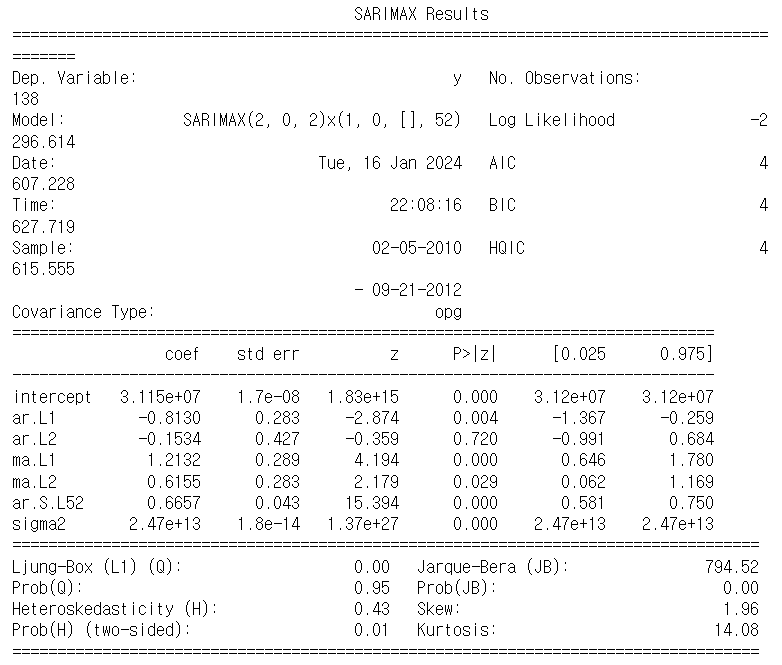
2. ARIMA 분석
- 정상성 확인을 위해 adf 검정을 통해서 p-value값 확인.
- 귀무가설 기각 못하면 차분, 지연, 로그 등을 이용해 정상 시계열을 만들어야 한다.
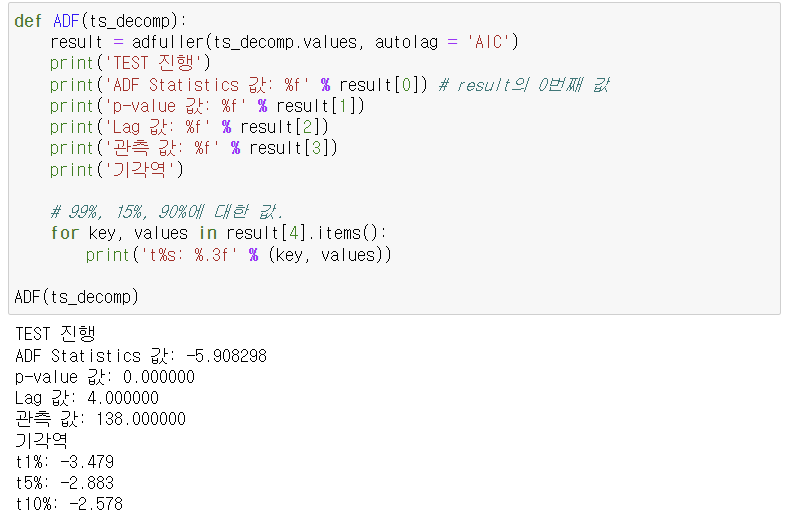


# ARIMA 모델의 p, d, q란?
- AR (p): 시계열 값이 과거 p 시점만큼 앞선 시점까지의 값에 의존할 때 쓰는 모형.
- MA (q): 시계열 값이 과거 q 시점만큼 앞선 시점까지의 오차에 의존할 때 쓰는 모형.
- d차 차분: 연이은 관측값의 차이를 d번 한 것.
- p: AR 부분의 차수.
- d: 차분의 정도.
- q: MA 부분의 차수.
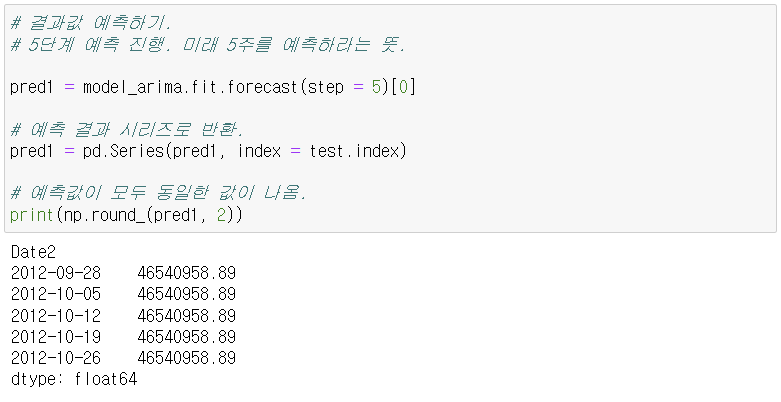
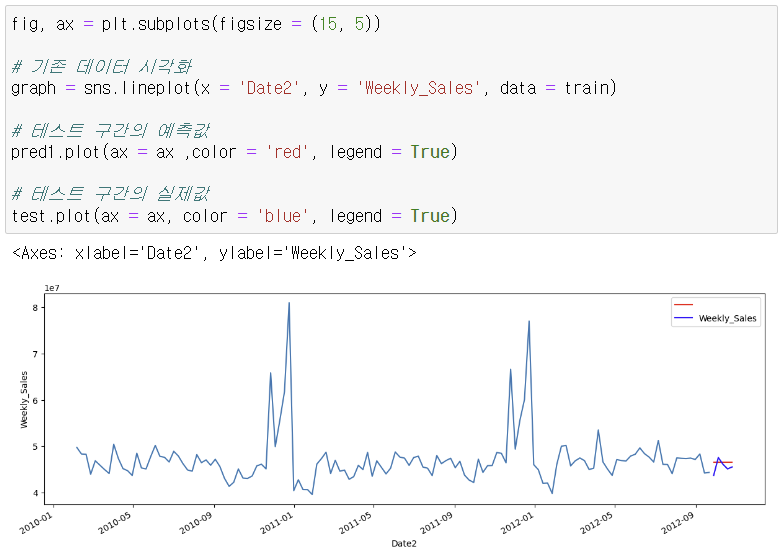
- 시각화 결과: 짧은 기간을 예측했기 때문에 좋지 않은 결과 나올 수 있다.
- 계속 동일한 값이 나오는 것은 잘못된 모델과 결과이다.
- ARIMA 모델은 주기성, 계절성 있는 데이터의 추세, 패턴 관련 학습을 놓칠 수 있다.
- 이 부분을 놓치지 않으려면 auto_arima를 활용해야 한다.
2-1. auto_arima
- 자동으로 p, d, q를 바꿔가면서 계수를 추정.
- 모형별로 정보 기준을 계산하여 최적의 값을 내는 모형.
- 모델 학습 전후로 사용자가 확인해야 할 두 가지.
- 모델 활용 전 시각화로 패턴을 확인.
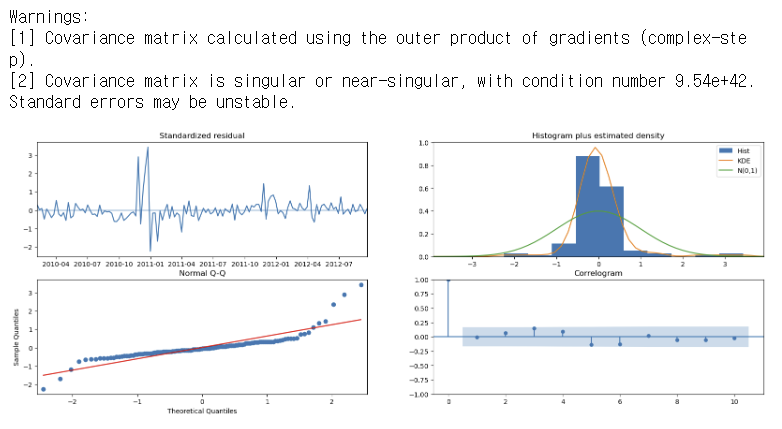
- 예측 결과 잔차가 백색잡음인지, 잔차가 정상성 만족하는지 직접 확인.
# auto_arima의 파라미터
- y: np.nan과 np.inf 값이 없는 분석 대상, 시계열 데이터.
- X: An optional 2-d array of exogenous variables. 외생적 특징이 있는 데이터일 경우 외생 변수의 2차원 배열을 선택적으로 추가해야 함. 상수나 추세 포함되지 않은 데이터여야 함. (default = None)
- start_p: p의 시작 값, 자동 회귀("AR") 모델의 차수. (default = 2)
- d: 1차 차분의 정도. None인 경우 테스트 결과에 따라 값이 자동으로 선택. (default = None)
- start_q: 이동 평균("MA") 모델의 차수인 q의 시작 값. (default = 2)
- max_p: p의 최대값(포함). max_p >= p여야 함. (default = 5)
- max_d: d의 최대값이거나 비계절적 차이의 최대 수. max_d >= d여야 함. (default = 2)
- max_q: q의 최대값(포함). max_q >= q여야 함. (default = 5)
- start_P: 자기회귀 부분의 차수인 P의 시작 값. (default = 1)
- D: 계절 차분의 정도. None이면 seasonal_test 결과에 따라 자동으로 값 선택됨. (default = None)
- start_Q: 계절 모형의 이동 평균 부분의 차수인 Q의 시작 값. (default = 1)
- max_P: P의 최대값(포함). max_P > P여야 함. (default = 2)
- max_D: D의 최대값. max_D > D여야 함. (default = 1)
- max_Q: Q의 최대값(포함). max_Q > Q여야 함. (default = 2)
- max_order: 모델 선택이 단계적이지 않은 경우 p+q+P+Q의 최대값. max_order가 None이면 최대 순서에 대한 제약이 없음을 의미함. (default = 5)
- m: 각 계절의 기간 수. 분기별 = 4, 월별 12, 연간(비계절) = 1. (default = 1)
- seasonal: 계절성 데이터 여부. seasonal = True인데 m = 1인 연간 데이터라면 seasonal = False로 진행됨. (default = True)
- stationary: 시계열이 고정되어 있고, d = 0으로 설정되어야 하는지. (default = False)
- information_criterion: 최상의 ARIMA 모델을 선택하는 데 사용되는 정보 기준. ('aic', 'bic', 'hqic', 'oob') 중 하나. (default = 'aic')
- alpha: 유의성 테스트 위한 테스트 수준. (default = 0.05)
- test: (stationary = False) & (d = None)인 경우 정상성 탐지 위해 사용할 단위근 테스트 유형. (default = 'kpss')
- seasonal_test: (seasonal = True) & (d = None)인 경우 어떤 계절 단위근 테스트가 사용되는지 결정. (default = 'ocsb')
- stepwise: 최적의 모델 매개변수를 식별하기 위해 단계적 알고리즘을 사용할지 여부. (default = True)
- n_jobs: (stepwise = False)이고 그리드 검색인 경우 병렬로 맞출 모델 수. -1은 가능한 많이 지정하라는 뜻. (default = 1)
- start_params: ARMA(p,q)의 시작 매개변수입니다. None인 경우 기본값은 ARMA._fit_start_params에 의해 제공됨. (default = None)
- method: scipy.optimize의 어떤 솔버(해결책 제공자 또는 프로그램)가 사용되는지 결정. ('newton', 'nm', 'bfgs', 'lbfgs', 'powell', 'cg', 'ncg', 'basinhopping') 중 하나. (default = 'lbfgs')
- trend: 추세 매개변수. with_intercept = True이면 추세가 사용됨. False인 경우 추세는 절편 없음 값. (default = None)
- maxiter: 함수 평가의 최대 횟수. (default = 50)
- offset_test_args: 오프셋(d) 테스트의 생성자에 전달할 인수. 자세한 내용은 pmdarima.arima.stationarity. (default = None)
- seasonal_test_args: 계절 오프셋(D) 테스트의 생성자에 전달할 인수. 자세한 내용은 pmdarima.arima.seasonality. (default = None)
- suppress_warnings: Suppress_warnings = True이면 ARIMA에서 오는 모든 경고를 띄우지 않음. (default = True)
- error_action: 어떤 이유로든 ARIMA를 적합할 수 없는 경우 이는 오류 처리 동작을 제어. 선형 대수 오류, 수렴 오류 또는 정상성 또는 입력 데이터와 관련된 여러 가지 문제로 인해 모델 적합이 실패할 수 있음. (default = 'warn')
- trace: fits에 상태 출력할지 여부. False 값은 디버깅 정보를 인쇄하지 않음. (default = False)
- random: 그리드 검색과 마찬가지로 auto_arima는 하이퍼 매개변수 공간에 대해 "무작위 검색"을 수행하는 기능을 제공. random = True인 경우 전체 검색이나 단계적 검색을 수행하는 대신 n_fits ARIMA 모델만 적합. (이 옵션이 모든 작업을 수행하려면 단계적 False여야 함) (default = False)
- random_state: random = True인 경우의 PRNG. 복제 가능한 테스트 및 결과 보장. (default = None)
- n_fits: Random = True이고 무작위 검색 수행될 경우 n_fits = 적합할 ARIMA 모델의 수. (default = 10)
- return_vaild_fits: True = 목록의 모든 유효한 ARIMA 피팅이 반환. False = 가장 적합한 항목만 반환. (default = False)
- out_of_sample_size: ARIMA 클래스는 "out of bag" 샘플 점수를 유지하기 위해 지정된 경우 데이터의 일부에만 적합할 수 있음. 이는 검증 예제로 유지하고 사용할 시계열 꼬리의 예제 수. 미래 예측 값이 내생 벡터의 끝에서 발생. (default = 0)
- scoring: 검증을 수행하는 경우(out_of_sample_size > 0) 샘플 외부 데이터의 점수를 매기는 데 사용할 측정 항목. ('mse', 'mae') 중 하나. (default = 'mse')
- scoring_args: 점수 측정항목에 전달될 키워드 인수 딕셔너리. (default = None)
- with_intercept: 절편 용어를 포함할지. 검색에서 차이점 검색어의 합이 명시적으로 True 또는 False로 설정되는 지점까지 True처럼 동작. (default = "auto")
- sarimax_kwagrs: ARIMA 생성자에 전달할 키워드 인수. (default = None)
- **fit_args: ARIMA.fit() 메서드에 전달할 키워드 인수 딕셔너리. (default = None)
https://alkaline-ml.com/pmdarima/modules/generated/pmdarima.arima.auto_arima.html
pmdarima.arima.auto_arima — pmdarima 2.0.4 documentation
Parameters:y : array-like or iterable, shape=(n_samples,) The time-series to which to fit the ARIMA estimator. This may either be a Pandas Series object (statsmodels can internally use the dates in the index), or a numpy array. This should be a one-dimensi
alkaline-ml.com


3. prophet 시계열 분석
- facebook에서 만든 모델.
- 차분, 정상 시계열, p-value 등 개념을 잘 모르더라도 사용할 수 있는 쉬운 모델.
- 컬럼명을 ds, y로 바꿔 주고, index는 숫자로 변경해 줘야 함.
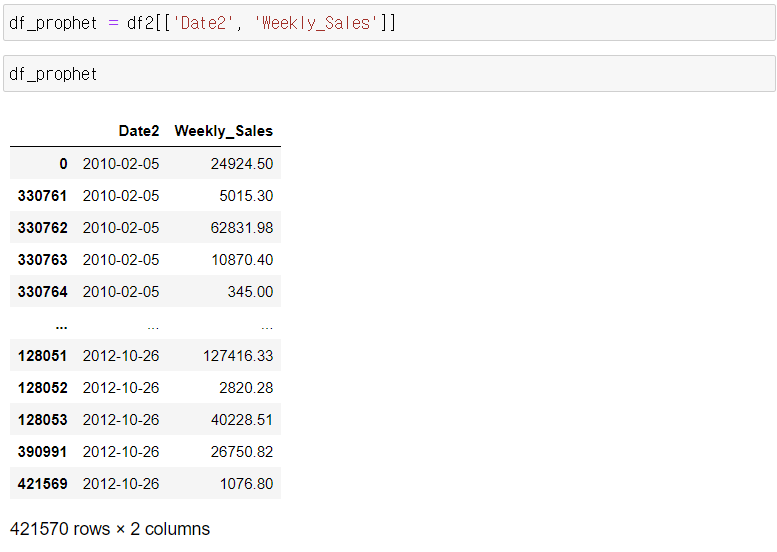
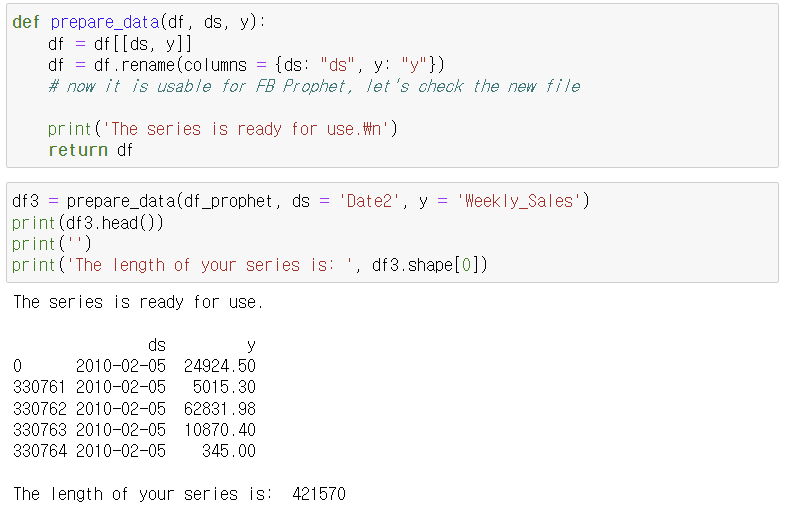
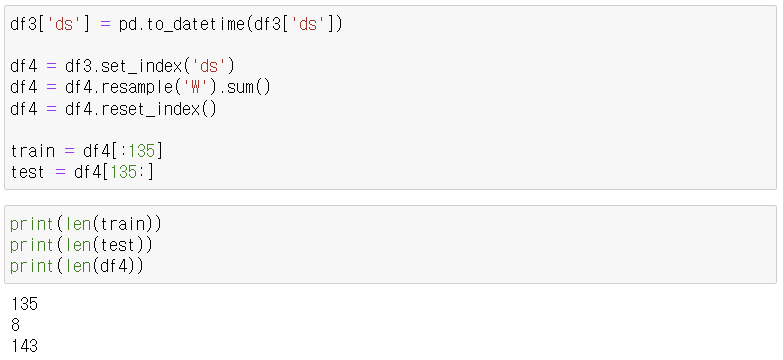

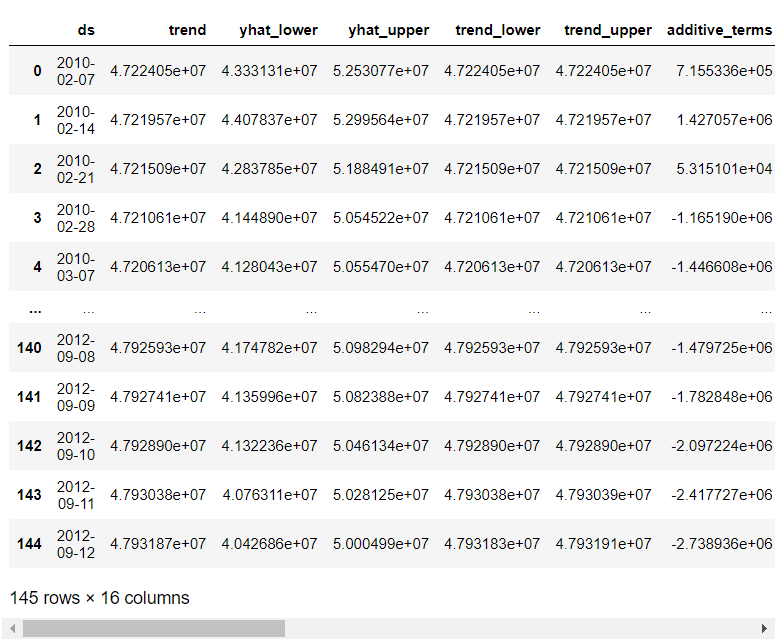




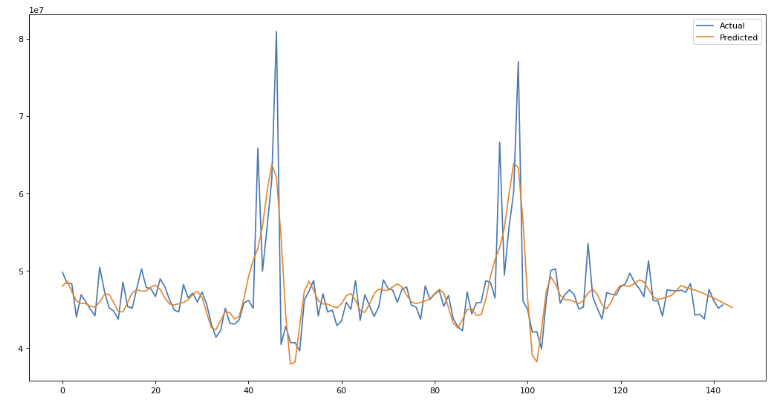

4. 내용 정리
- 추세와 시계열이 반영된 데이터는 동일한 값만 나오는 문제가 발생할 수 있다.
- 그래서 정상성 가진 데이터로 만들려고 하는 것이다.
- 이를 해결하기 위해 auto arima와 같은 트렌드 반영한 모델도 있다.
- 간단한 분석으로 미래 예측을 하는 모델로는 prophet이 있다.
- 전처리 부분이 가장 오래 걸리는 작업.
- 해당 데이터 전처리 고민하고, 다양하게 값을 바꾸고 예측값과 실제값을 비교해 보기.
'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 12주차 필수 과제 1 - 문자열 관련 함수 총 정리 (1) | 2024.02.01 |
|---|---|
| [BDA 데분기] 12주차 - 문자열 관련 함수 (0) | 2024.01.31 |
| [BDA 데분기] 10주차 - kaggle master 코드 분석 (1) | 2024.01.31 |
| [BDA 데분기] 9주차 필수 과제 2 - 시계열 데이터 분석 및 시각화 (0) | 2024.01.31 |
| [BDA 데분기] 9주차 필수 과제 1 - 반복문으로 데이터 시각화 (0) | 2024.01.31 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



