
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 보간법
- MSE
- stopwords
- 데이터프레임
- 이상치
- 선형보간
- subplots
- 결측치대체
- sklearn
- Python
- 누락값
- 파이썬
- DataFrame
- 결측치
- SimpleImputer
- 전처리
- koNLPy
- KoNLP
- Outlier
- interpolate
- matplotlib
- IterativeImputer
- 불용어
- value_counts
- join
- Boxplot
- BDA
- 대치법
- countplot
- Seaborn
Archives
- Today
- Total
ACAIT
[BDA 데분기] 4주차 - 보간법 보충, sklearn, statsmodels 본문
1. 보간법 보충 자료
1-1. Sklearn impute
- 결측치 보완 방법 여러 개. 아래는 다변량 보완 방법 코드.
- simplemputer: 간단하게 메우는 방식
- iterativeImputer: 오늘 할 예정
- KNNImputer: 거리
- MissingINdicator
1-2. Iterative Imputer
- 결측치를 대체할 때 단순 선형 회귀 대치를 하면?
- 예시) 연령과 소득 데이터에서 소득에만 결측치. 연령과 소득에 대한 관계로 선형관계가 있다면 상관성을 보고 둘의 회귀식을 관계로 단순하게 결측치를 대체하는 것. 연령이 높아지면 소득도 올라간다는 패턴으로 단순히 잡아가게 됨. 이런 식으로 할 수는 있으나 너무 단순함.
- 확률적 회귀 대치법
- 단순 접근이 아니라 회귀식에 확률 오차항 추가해서 확률적으로 회귀 대치 진행. 이것도 한계가 있긴 함.
- 예시) 통계적으로 표본 오차 문제 등 여러 문제가 발생하게 됨. 해결하기 위해서 다중 대치법을 사용함.
- 다중 대치법
- 위의 방법들을 보완하기 위해 단순 대치를 여러번 수행하는 것.
- 예시) 가상 데이터 샘플을 뽑아서 대치값을 통해 분석하고 결국 최종 결측치를 대체할 값을 선정하는 것.
- 자료 좌측 그림 설명: 서로 다른 결측치를 대체할 수 있는 다른 변수들과 함께 데이터 표본 추출하고 진행.
- 여기서 분석을 하게 된다는 것은?
- 생성된 데이터들에서 통계적으로 모수를 추정하거나 추정치, 표준 오차 등 계산해서 가장 전체 각 데이터셋 추정치 표준오차가 계산된 n개의 데이터셋 중에 결합해서 최종 결측치 대치값을 산출하는 조건.
- 몬테카를로 MCMC
2. 기존에 배운 내용 복습
- 평균대치, 선형보간
- sklearn interative imputer를 사용해서 실제 결측값 대체하고
- 해당 결측값을 대체한 것을 회귀분석으로 mse 차이가 어떻게 나오는지 비교.
- mse 오차에 대한 개념: 예측한 값과 실제 값의 차이
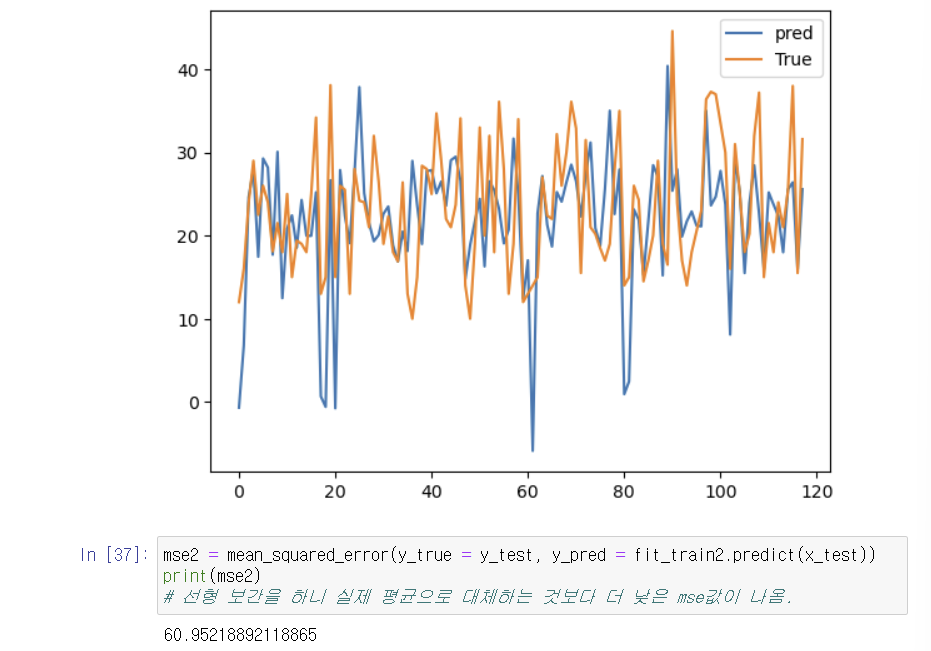
Q. 선형 보간의 경우는 결국 interpolate 기존 데이터 보고 결측 메우는 방식인데,
해당 방식이 과연 정말 데이터의 올바른 결측치 대체 방법인지?
이 내용을 확인하기 위해 코드 실행을 해 보겠습니다.



3. 대체 방법
3-1. 평균으로 대체
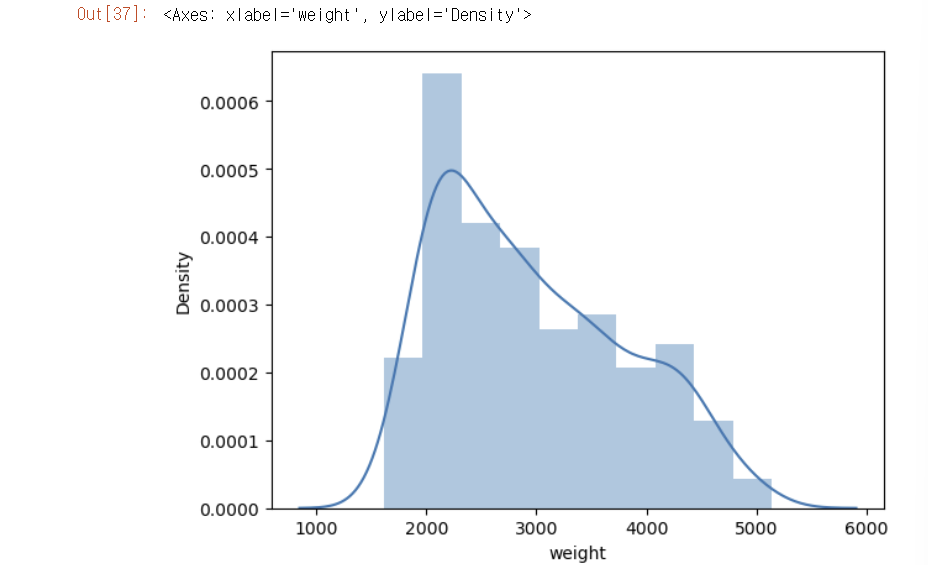
- cylinders, displacement, horsepower, weight 열마다 29개의 Nan값이 생성됨.





3-2. 보간법 이용(선형 보간법)

3-3. sklearn 패키지 - iterativeImputer
- 하이퍼 파라미터가 매우 다양
- 모델링 할 때 여기 있는 모든 하이퍼 파라미터 배우는데
- 공식 sklearn 홈페이지 보면서 하면 좋음


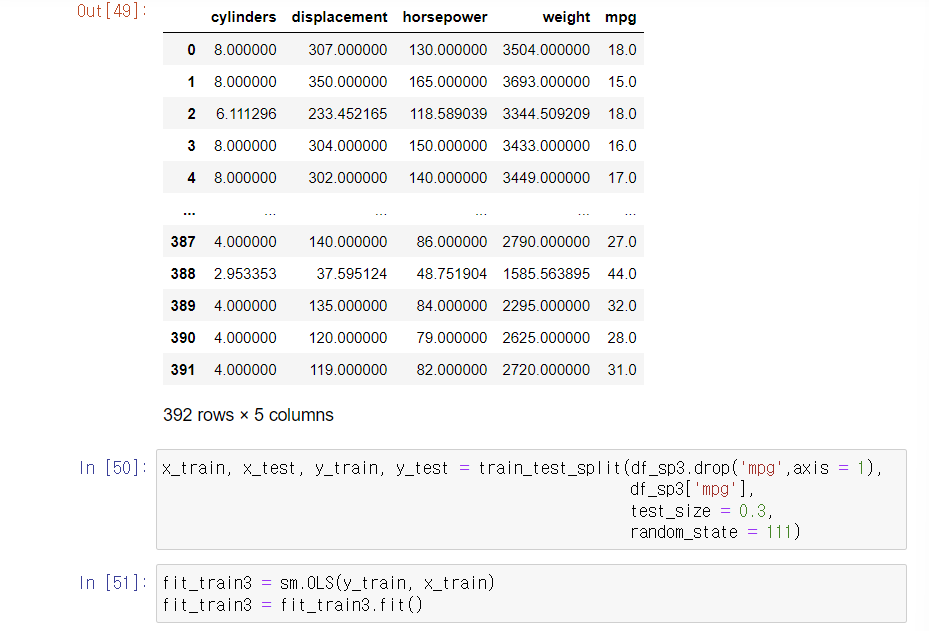
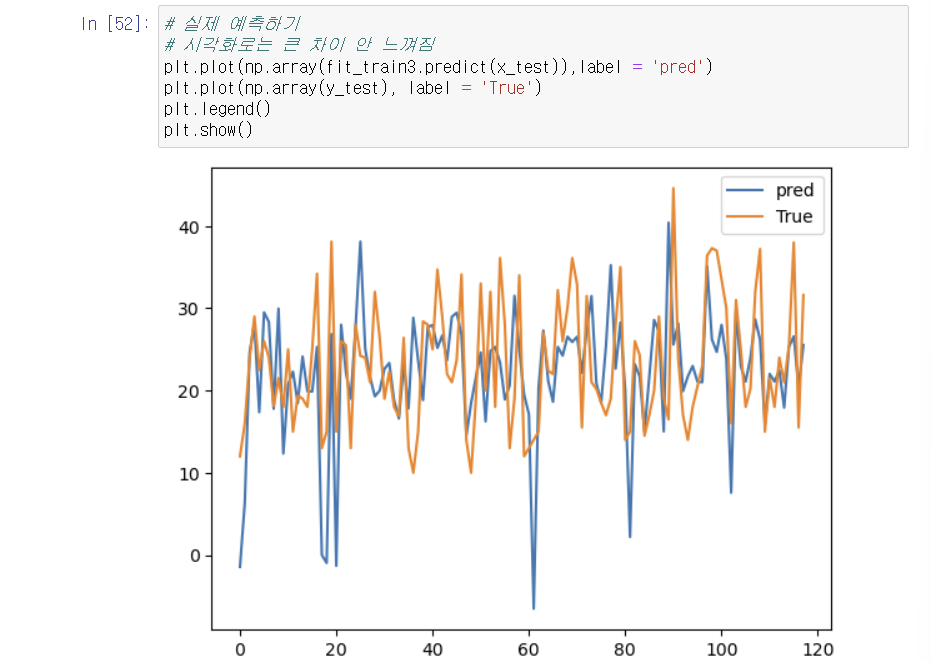
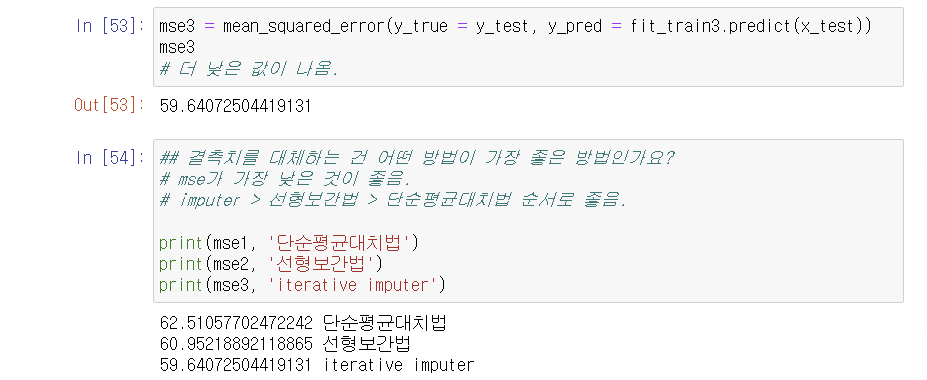
3-4. 이 지표를 가지고 어떻게 해석?
Q. 모든 데이터를 이런 식으로 sklearn 대치하면 되는 건가?
A. 아니다.
- 단순하게 평균, 선형보간, iterative 등 어떤 게 가장 좋다고 할 수 없음.
- 데이터 관계, 분포, 데이터에 대한 도메인 지식이 필수적으로 있어야 함.
- 데이터 분석가가 도메인 지식 없이 단순 수치로 싸우고 판단하면 한 쪽으로만 치우치는 경향
- 데이터 분석가가 해석 불가. 설득 불가.
- 해당 데이터에 why라는 질문에 답할 수 있으려면 질문을 찾을 수 있어야 함.
- why를 어떤 식으로 설명? 기존 데이터의 분포와 관계 잘 이해하고 있어야 함.
- 결측치를 대처하는 방법 자체가 위의 방법대로 진행하려면 해당 방법에 대한 로직 정확히 이해 필요.
- 무엇보다 중요한 건 현재 데이터 분포에 대한 정확한 이해.
- 평균으로만 대체하는 것이 오히려 로직상으로 맞을 수도 있음.
- 서베이 데이터에 무응답 데이터는 다른 데이터와 관계로 대체가 아니라 무응답이므로 0으로 대체한다는 도메인 로직을 알아야 함.
※ 결측치 대체할 때
- 꼭 도메인에 대한 지식 가지고 컬럼 바라보고
- 각 컬럼간 데이터 분포와 '특히' y값 분포도 꼭 살펴보면서 어떤 결측치 대체 방법을 사용할지 고민하고 선택해야 함.







'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 4주차 필수 과제 2 - 시계열 데이터 결측치 대체, 시각화 (0) | 2024.01.31 |
|---|---|
| [BDA 데분기] 4주차 필수 과제 1 - sklearn SimpleImputer (0) | 2024.01.31 |
| [BDA 데분기] 3주차 필수 과제 - interpolation 보간법 응용 (0) | 2024.01.08 |
| [BDA 데분기] 3주차 - 결측치, 누락값, 이상치 처리 방법 (0) | 2024.01.08 |
| [BDA 데분기] 2주차 - Python 기초 문법 (1) | 2024.01.08 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



