
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 누락값
- 결측치
- 이상치
- join
- koNLPy
- 결측치대체
- IterativeImputer
- Boxplot
- 전처리
- countplot
- matplotlib
- 선형보간
- 불용어
- sklearn
- interpolate
- DataFrame
- Seaborn
- MSE
- 보간법
- BDA
- KoNLP
- subplots
- 데이터프레임
- stopwords
- value_counts
- Outlier
- 대치법
- 파이썬
- SimpleImputer
- Python
Archives
- Today
- Total
ACAIT
[BDA 데분기] 4주차 필수 과제 2 - 시계열 데이터 결측치 대체, 시각화 본문
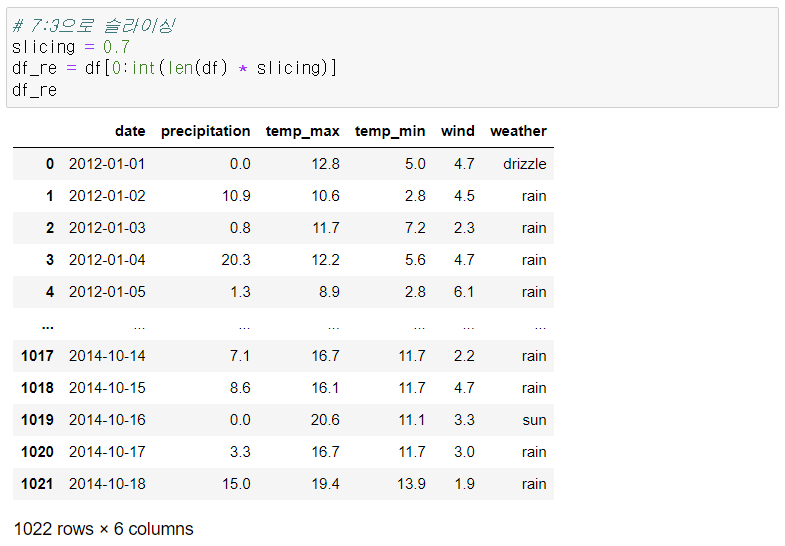
시계열 데이터로 결측치 생성 및 대체, 시각화를 진행해 보도록 하겠습니다.
- seattle-weather.csv (출처: kaggle)
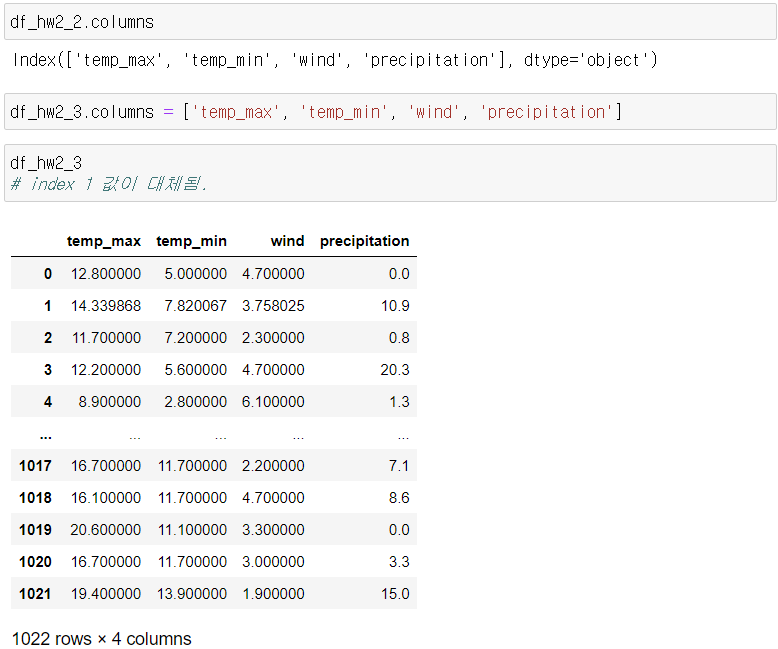
- date, precipitaion, temp_max, temp_min, wind, weather 여섯 개의 컬럼으로 이루어짐.
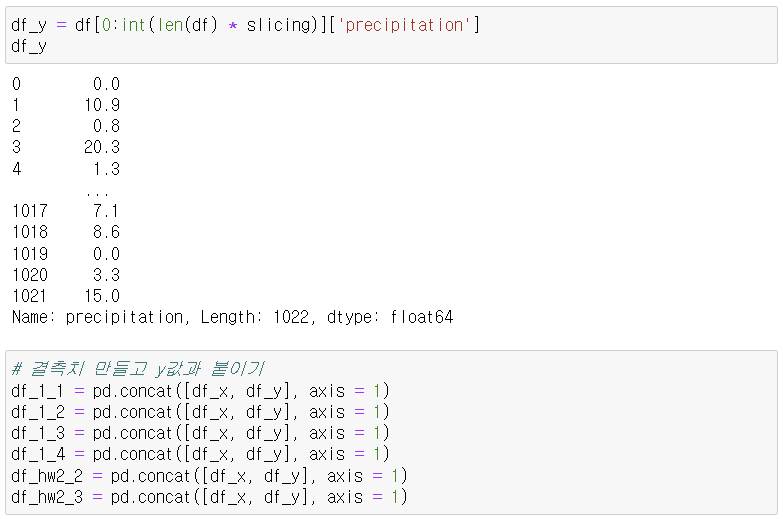
- y값을 precipitation으로 설정.
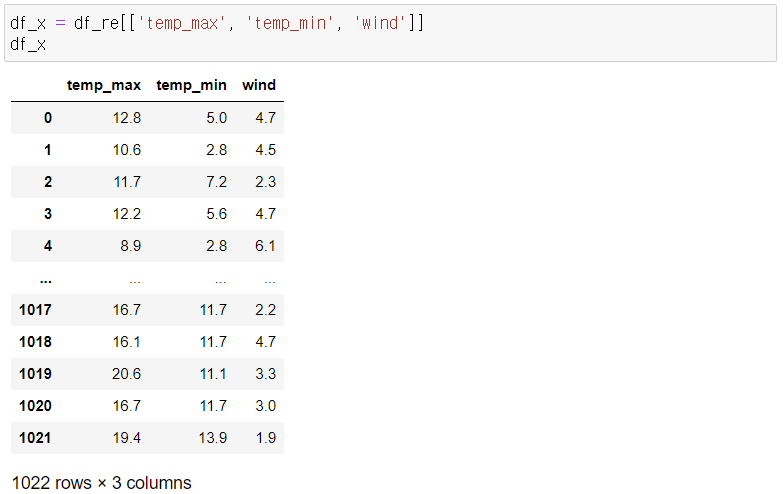
- 이외 사용할 컬럼은 temp_max, temp_min, wind.
- 시계열 데이터이므로 train_test_split 사용하면 안 됨.
- 따라서 인덱스 기준으로 데이터 분리해서 진행. (전체 데이터 중 7:3 비중)
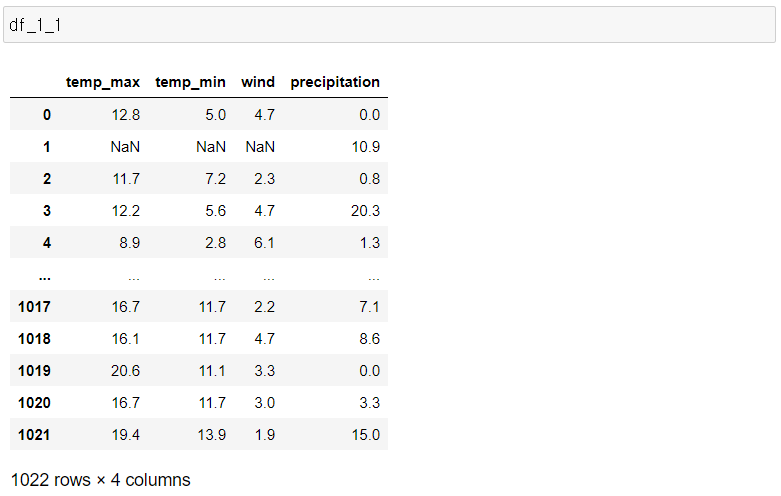
- 결측값은 모든 컬럼에 최소 50개 이상 생성.

1. IterativeImputer(회귀대치)의 주요 파라미터
- estimator(추정량): estimator object, default = BayesianRidge()
- missing_values(결측치) = int or np.nan, defaut = np.nan
- sample_posterior = bool, default = False
- max_iter(최대 반복 횟수) = int, default = 10
- tol(tolerance, 허용 오차) = float, default = 1e-3
- n_nearest_features = int, default = None
- 결측값 추정 시 사용할 다른 속성 수.
- 절대상관계수 사용하여 측정.
- 기능 수 많을 때 상당한 속도 향상.
- None인 경우 모든 기능 사용.
- initial_strategy = {'mean', 'median', 'most_frequent', 'constant'}, default = 'mean'
- imputation_order = {'ascending', 'descending', 'roman', 'arabic', 'random'}, default = 'ascending'
- 기능 전가 되는 순서.
- 오름차순, 내림차순, 좌에서 우로, 우에서 좌로, 무작위 순서.
- skip_complete = bool, default = False
- fit(학습) 때 값이 있었고 transform(테스트) 때 값이 없을 때
- Ture = fit값 그대로. False = 계산값.
- min_value = {float, array-like of shape (n_features, )}, default = -np.inf
- min_value = {float, array-like of shape (n_features, )}, default = np.inf
- 둘의 default = (-∞, ∞)
- verbose(상세한 로깅 출력) = int, default = 0
- random_state = {int, RandomState instance, None}, default = None
- add_indicator(출력값 보여주는 객체) = bool, default = False
2. y축과 각 데이터들의 관계 비교
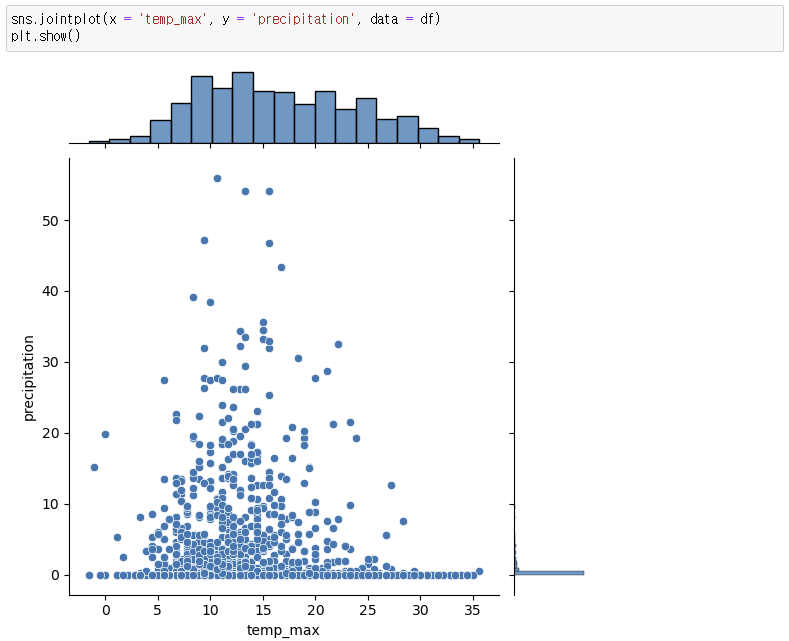
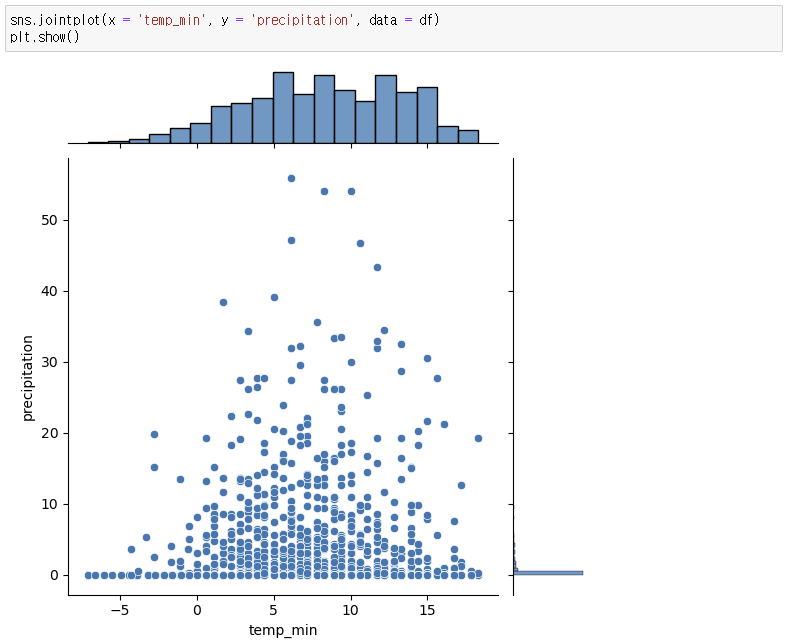
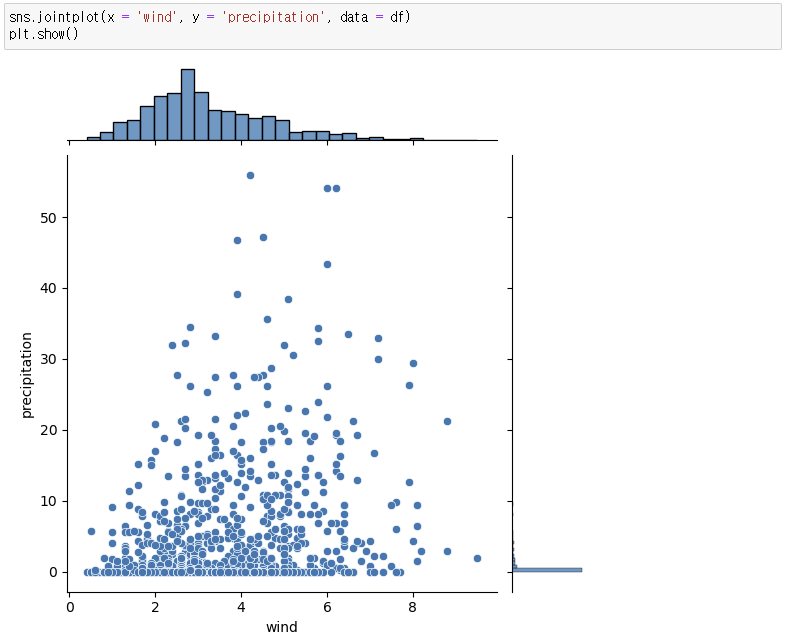


3. 대체 실습
3-1. fillna()
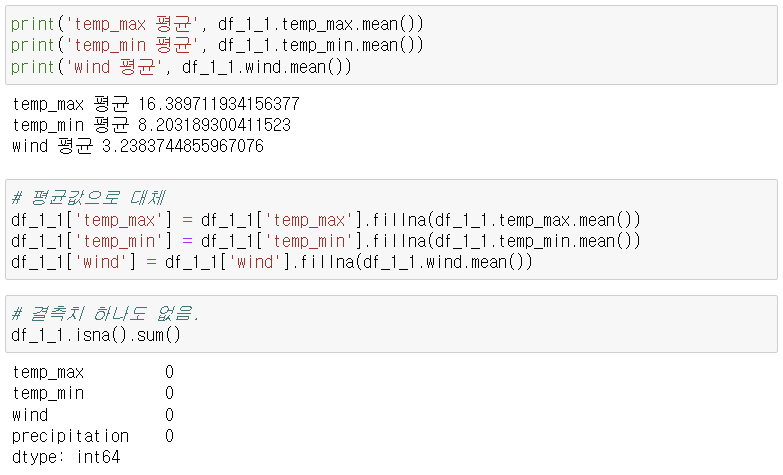
3-1-1. 평균으로 대체

- 평균으로 대체한 뒤 OLS방식 회귀분석



3-1-2. 중앙값으로 대체




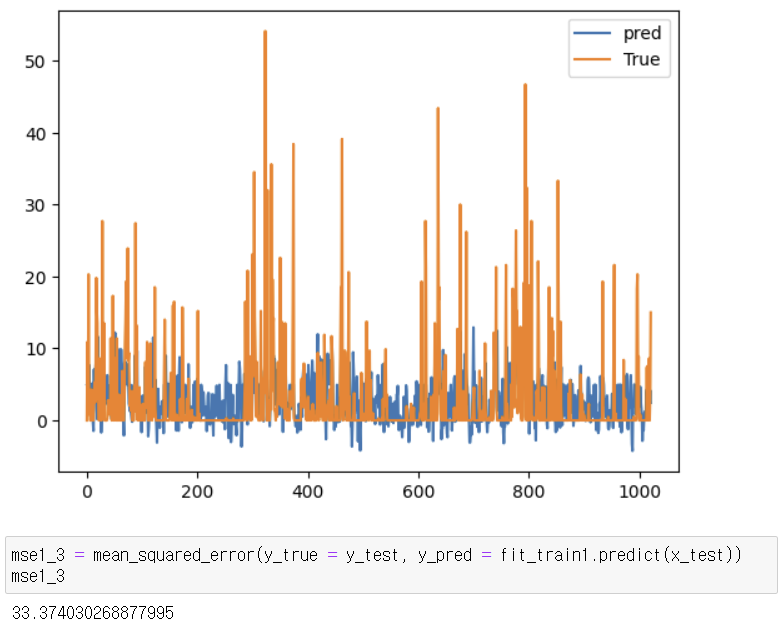
3-1-3. 최빈값으로 대체



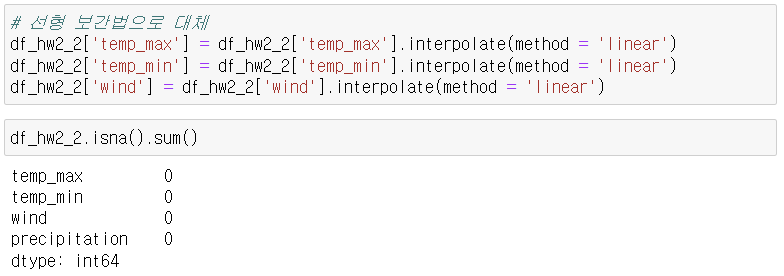
3-2. 선형 보간법으로 대체


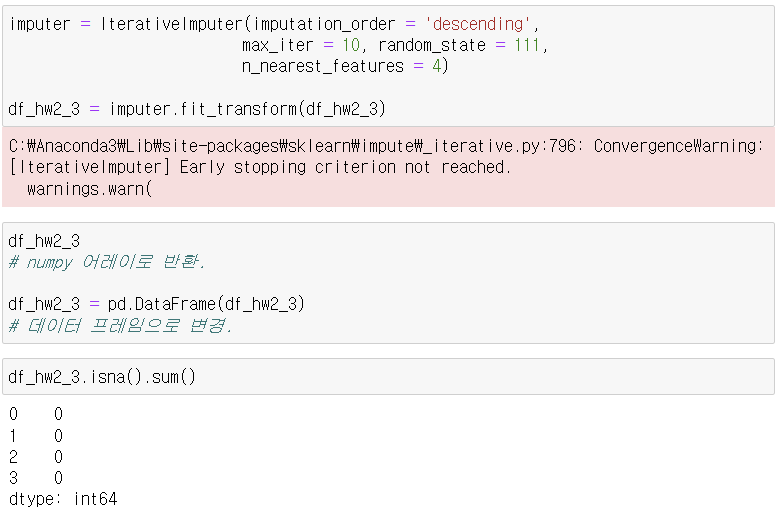
3-3. sklearn 패키지 - IterativeImputer

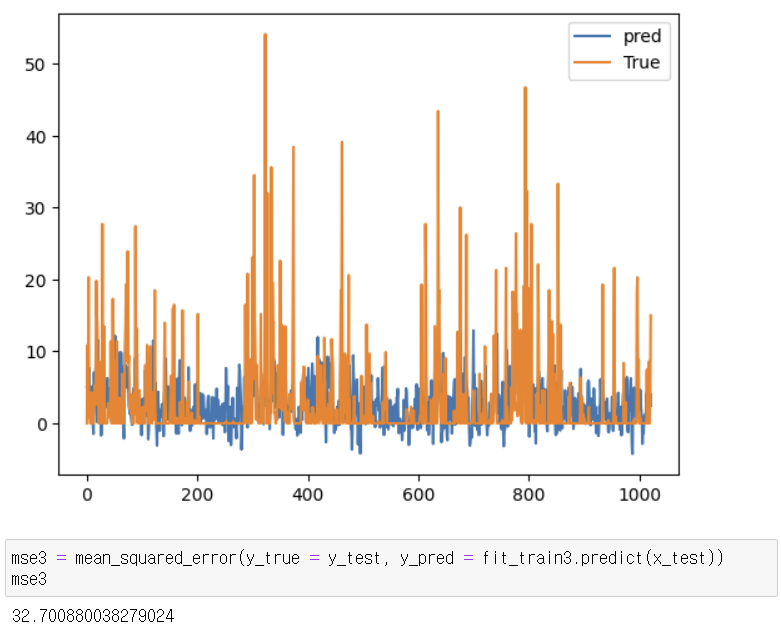
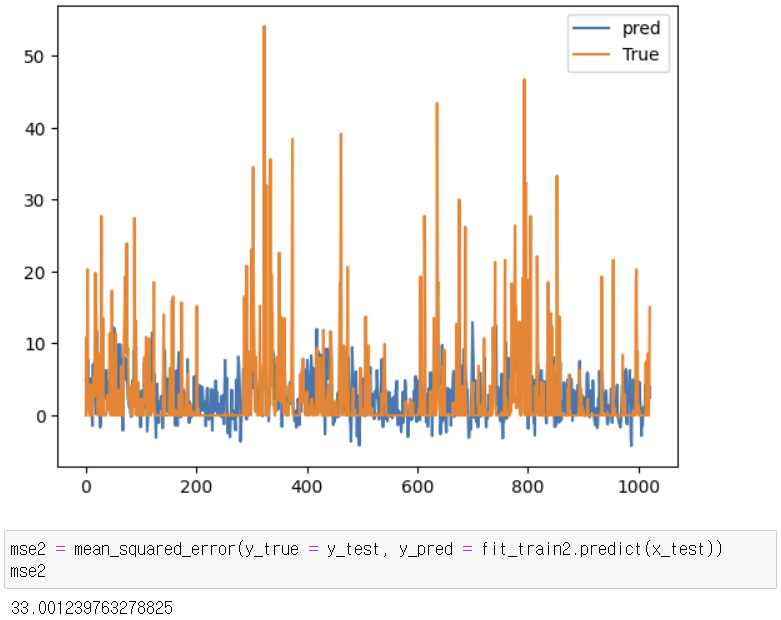
4. MSE값 비교
- 단순평균 대치법: 33.14034557114236
- 중앙값으로 대치: 33.14059829806533
- 최빈값으로 대치: 33.374030268877995
- 선형보간법: 33.001239763278825
- IterativeImputer: 32.700880038279024
'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 5주차 - 이상치, Outlier (0) | 2024.01.31 |
|---|---|
| [BDA 데분기] 4주차 필수 과제 정리 - SimpleImputer, 시계열 데이터 (0) | 2024.01.31 |
| [BDA 데분기] 4주차 필수 과제 1 - sklearn SimpleImputer (0) | 2024.01.31 |
| [BDA 데분기] 4주차 - 보간법 보충, sklearn, statsmodels (1) | 2024.01.08 |
| [BDA 데분기] 3주차 필수 과제 - interpolation 보간법 응용 (0) | 2024.01.08 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



