
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- Outlier
- value_counts
- Python
- 파이썬
- Boxplot
- 이상치
- KoNLP
- countplot
- 선형보간
- join
- sklearn
- 결측치대체
- subplots
- SimpleImputer
- MSE
- matplotlib
- 대치법
- interpolate
- 전처리
- 누락값
- BDA
- 보간법
- IterativeImputer
- 데이터프레임
- Seaborn
- stopwords
- DataFrame
- koNLPy
- 불용어
- 결측치
Archives
- Today
- Total
ACAIT
[BDA 데분기] 5주차 - 이상치, Outlier 본문
이상치와 관련된 내용을 복습하도록 하겠습니다.
- 결측치와 이상치는 다른 개념.
- 이상치(Outlier)는 값이 튀는 것.
- Outlier detection: 예상 범위를 벗어나는 것을 잡아야 함.
- Outlier로 회귀에 문제가 있는 이유: 하나의 직선을 그릴 때 해당 값 때문에 기울기가 많이 바뀜.
이상치 하나 때문에 다른 데이터도 설명하기 어려워지고, 회귀식에 영향을 미친다.
1. 이상치 찾는 방법
- 정규분포: 정규분포를 이룰 때 데이터 스케일링 작업 진행.
- IQR: Interquartile range의 약자로써 Q3 - Q1를 의미.
"어디까지가 이상치 데이터다" 라고 판단하는 기준 중 하나. - Isolation Forest: 데이터 트리 기반으로 나누고, 한쪽은 분류를 못하게 되면
이상치라고 생각하고 분류되는 경우도 있음. - DBScan: 밀도 기반. 군집 형성되지 않은 Noise가 이상치.
- 데이터 분석가의 도메인 지식으로 이상치 선정도 가능.
비즈니스, 데이터 로직 다 이해하고 이건 이상치이기 때문에 필터 걸어서 제외함.
2. 정규분포, IQR 이상치 관련 차이
- 식을 생각해 보면 정규분포는 평균이 들어가서 이상치에 민감, 영향을 받음.
IQR은 값에 대한 평균이 아닌 범위(range)라서 이상치 영향을 상대적으로 덜 받는다.
3. Outlier 잘못된 편견
- 극단적 값이라 무조건 제거한다고 생각 > 문제가 될 수 있다.
- 이상치 자체가 의미 있는 데이터일 수도 있기 때문.
- 데이터 분포 기준의 이상치 > 이상치라고 보기엔 실제 군집 or 데이터가 만들어진 것일 수도 있다.
- (ex. 백화점 고객 데이터 - 일반, vip 다름. 구매 금액 시각화 시 vip 고객 내역이 outlier.
백화점 입장에서는 vip 고객 데이터 제거가 아니고 집중해야 하는 데이터일 수도 있음.)
- (ex. 백화점 고객 데이터 - 일반, vip 다름. 구매 금액 시각화 시 vip 고객 내역이 outlier.
- 데이터 분포가 이상치와 기존 데이터 분포로 나뉜다면 의심은 가능. 제거해야 할지 활용해야 할지.
- 이상치 군집 형성된다면? 두 개의 군집으로 나눠 분석 가능.
- 두 개의 군집 나누지 않고 일반화되는 경우? 가중치를 두고 분석. outlier에 대한 값의 변수를 추가.
- 이상치 관련 작업에는 완전한 정답이 있는 것은 아니다.
- 데이터 목적에 맞는 이상치 제거에 대한 방법을 생각.
- 단순 수치 접근으로 이상치 제거, 성능 높이고 일반화할 수 있는 것인지 생각해 봐야 한다.

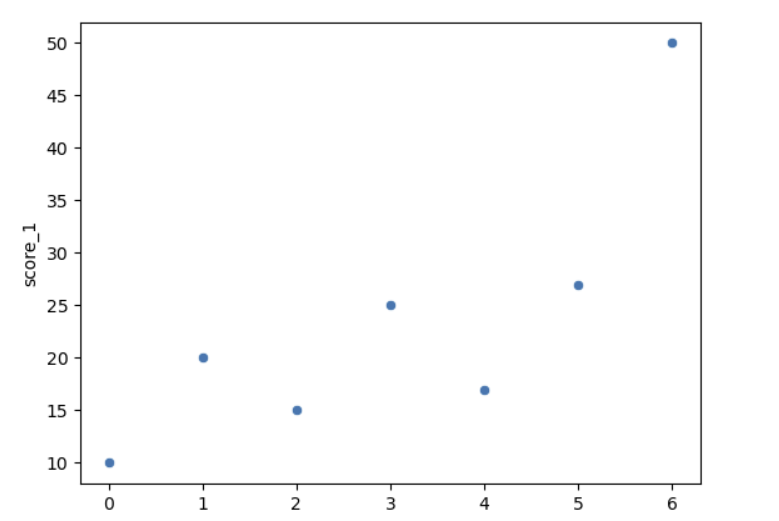

4. 예시 데이터로 이상치 확인
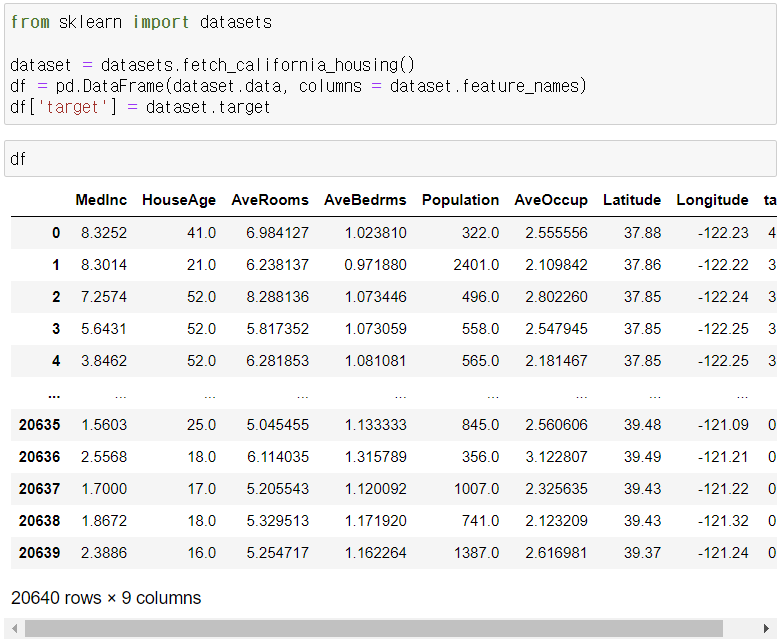




Q. 이상치를 제거하지 않고 회귀분석 RMSE 정도를 낮출 수는 없을까?
- 가중치나 새로운 변수를 만들면 정말 성능이 더 좋아지는 것인가?


5. 이상치 관련 작업
5-1. 베이스라인 모델 회귀분석

# train_test_split(arrays, test_size, train_size, random_state, shuffle, stratify)
- arrays: 분할시킬 데이터 입력
- test_size: 테스트 데이터셋의 비율, 갯수(default = 0.25)
- train_size: 학습 데이터셋의 비율, 갯수(default = test_size의 나머지)
- random_state: 데이터 분할 시 셔플을 위한 시드값(int나 RandomState로 입력)
- shuffle: 셔플 여부(default = True)
- stratify: 지정한 Data 비율 유지.
- ex) Label Set인 Y가 25%의 0과 75%의 1인 Binary Set일 때,
stratify = Y > 나누어진 데이터셋들도 0, 1을 25%, 75%로 유지하면서 분할.
- ex) Label Set인 Y가 25%의 0과 75%의 1인 Binary Set일 때,
- X_train, X_test, Y_train, Y_test : arrays에 데이터와 레이블을 둘 다 넣었을 경우의 반환이며,
데이터와 레이블의 순서쌍은 유지된다. - X_train, X_test : arrays에 레이블 없이 데이터만 넣었을 경우의 반환.


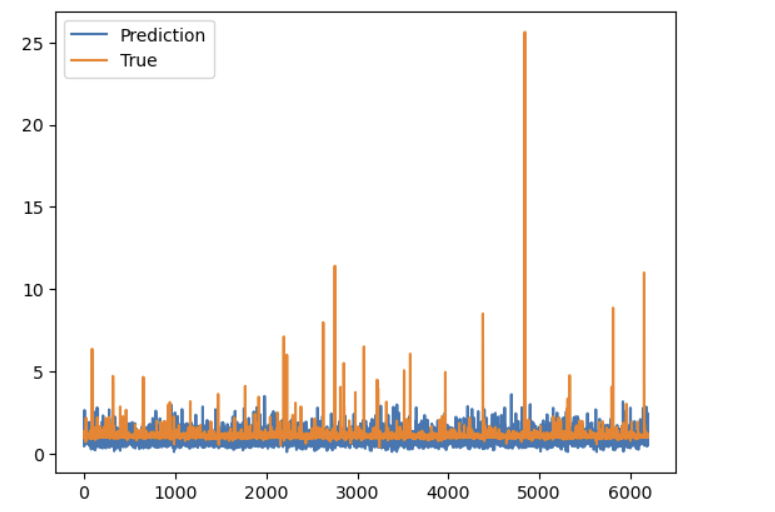

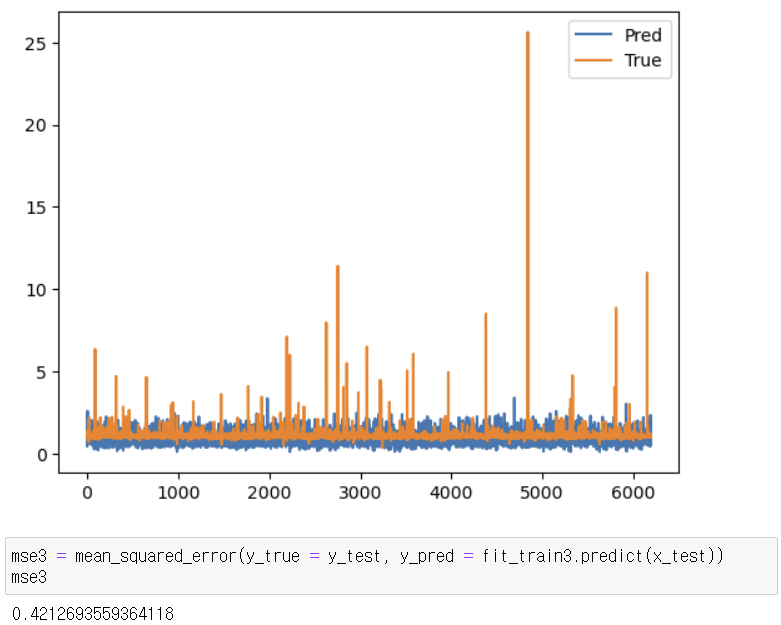
- 베이스라인 모델로 회귀분석 진행 시 mse = 0.43
5-2. 이상치 제거 - 열 MedInc 기준
- IQR 제거 진행
- IQR이란, Interquartile range의 약자로써 Q3 - Q1를 의미
- "어디까지가 이상치 데이터다" 라고 판단하는 기준 중 하나.
- Q3 - Q1: 사분위수의 상위 75% 지점의 값과 하위 25% 지점의 값 차이
- 통계치에 대한 개념으로 제거하면 아래와 같음.







5-3. 이상치 살리는 분석 진행 방법 - 가중치 부여
- 이상치의 가중치를 둔다고 하면 1, 아니면 0
- 혹은 반대로 가중치 둘 수도 있다
- 지금은 이상치에 가중치를 둬서 어떻게 진행되는지 확인(IQR 범위 벗어나면 1)





'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 6주차 - Series, DataFrame 관련 함수 (0) | 2024.01.31 |
|---|---|
| [BDA 데분기] 5주차 필수 과제 - 이상치 관련 분석 (0) | 2024.01.31 |
| [BDA 데분기] 4주차 필수 과제 정리 - SimpleImputer, 시계열 데이터 (0) | 2024.01.31 |
| [BDA 데분기] 4주차 필수 과제 2 - 시계열 데이터 결측치 대체, 시각화 (0) | 2024.01.31 |
| [BDA 데분기] 4주차 필수 과제 1 - sklearn SimpleImputer (0) | 2024.01.31 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



