
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 이상치
- subplots
- 불용어
- sklearn
- Python
- 데이터프레임
- interpolate
- KoNLP
- 보간법
- 결측치
- BDA
- Boxplot
- 결측치대체
- value_counts
- 대치법
- 누락값
- Seaborn
- 파이썬
- SimpleImputer
- stopwords
- Outlier
- koNLPy
- matplotlib
- MSE
- join
- 전처리
- countplot
- DataFrame
- 선형보간
- IterativeImputer
Archives
- Today
- Total
ACAIT
[BDA 데분기] 2주차 - Python 기초 문법 본문
- BDA 7기 활동을 하며 배운 내용을 블로그에 정리하고자 합니다.
- 1주차는 간단한 OT를 진행했고, 2주차부터 본격적인 수업을 진행했습니다.
- 키워드:
- 행 추출: query()
- 열 추출: []. [[]]
- 정렬: sort_values()
- 파생변수: assign(), lambda
- 그룹화: groupby().agg()
- 이어 배울 내용: merge(), concat(), loc, iloc, str()
0. 데이터 불러오기


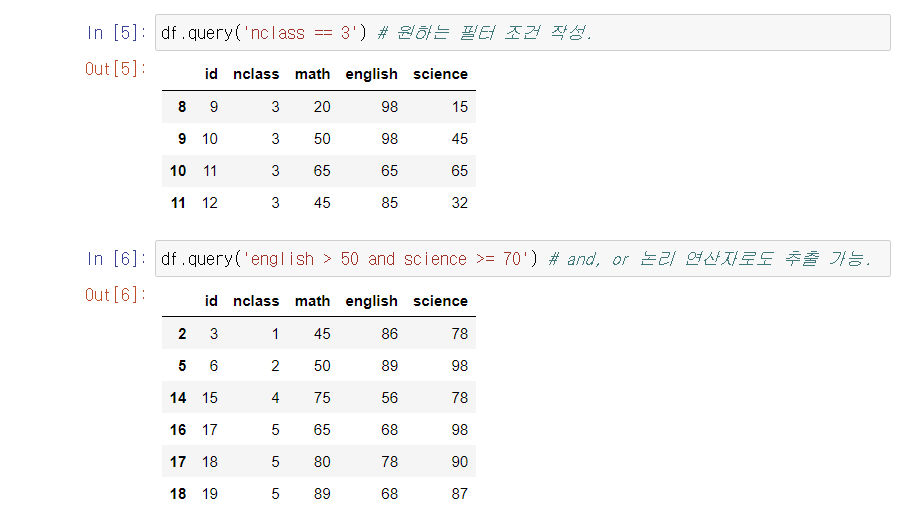
1. 행 추출: query()
2. 열 추출: [], [[]]


2-1. 열 제거 시 drop(columns='열 이름')





2-2. 메서드체이닝
- query()와 [], [[]]을 이용해서 열, 행 조건 동시 만족하는 데이터만 추출 가능.
- 메서드체이닝으로 문법이 이어진다.

3. 정렬: sort_values()
- 오름차순(default), 내림차순(ascending=False)



3-1. 두 개 이상 조건으로 정렬
- sort_values(['선순위 열', '후순위 열', ...], ascending=[True, False, ...])
- 정렬 조건과 오름차순, 내림차순 조건을 대괄호로 묶어 준다.

4. 파생변수
- 판다스에서 컬럼을 활용해 바로 파생변수 생성 가능
- apply() 이용하여 lambda 적용 가능
- loc, iloc로 접근해서 생성 가능
- assign() 함수 사용하여 가능
파생변수란?
- 외부변수, 파생변수가 있는데 통상적으로 내부 테이터로 새로운 데이터를 만드는 것.
- 왜 만드는가?
- 데이터 분석에 필요한 경우.(새 평균 기준점 가지고 분석. 매출 3개년치 성장율 등)
- 모델링 통해 피처에 대한 엔지니어링 진행 등.
4-1. 컬럼 이용해 파생변수 생성
- 새로운 컬럼 = 컬럼에 넣을 데이터




4-2. assign()
- df.assign(컬럼 명 = 컬럼에 넣을 데이터)







4-3. lambda식 활용


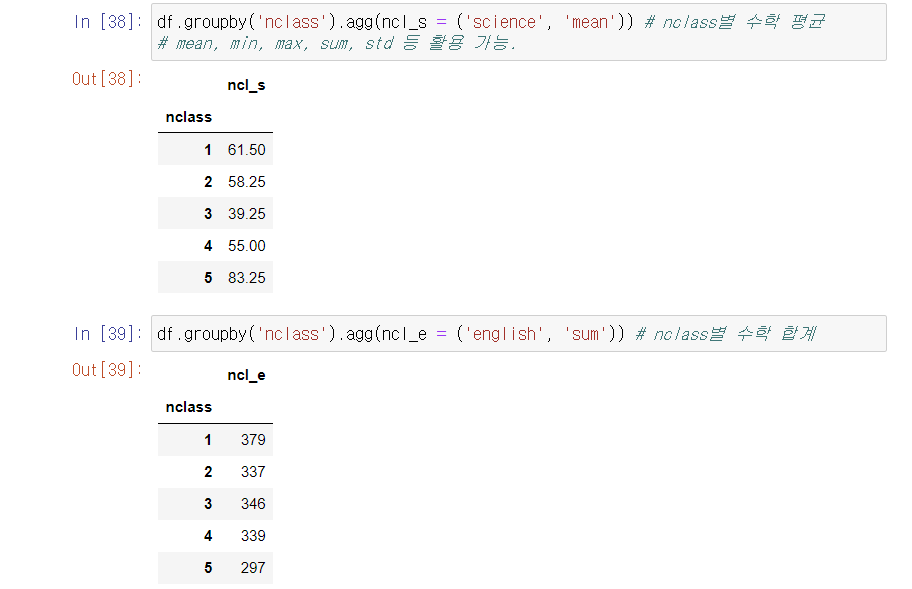
5. 그룹화: groupby()
- 그룹으로 묶는 것.
- 그룹별 통계치, 카운팅 등에 활용.
- df.groupby(기준 열).agg(새 변수명(변수, 요약 통계치))

'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 4주차 필수 과제 2 - 시계열 데이터 결측치 대체, 시각화 (0) | 2024.01.31 |
|---|---|
| [BDA 데분기] 4주차 필수 과제 1 - sklearn SimpleImputer (0) | 2024.01.31 |
| [BDA 데분기] 4주차 - 보간법 보충, sklearn, statsmodels (1) | 2024.01.08 |
| [BDA 데분기] 3주차 필수 과제 - interpolation 보간법 응용 (0) | 2024.01.08 |
| [BDA 데분기] 3주차 - 결측치, 누락값, 이상치 처리 방법 (0) | 2024.01.08 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



