
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- IterativeImputer
- 결측치
- value_counts
- matplotlib
- 파이썬
- Python
- KoNLP
- MSE
- 보간법
- Seaborn
- 불용어
- BDA
- koNLPy
- Boxplot
- Outlier
- 선형보간
- 대치법
- stopwords
- interpolate
- DataFrame
- countplot
- SimpleImputer
- 이상치
- 누락값
- 전처리
- subplots
- 데이터프레임
- join
- sklearn
- 결측치대체
Archives
- Today
- Total
ACAIT
[BDA 데분기] 12주차 필수 과제 2 - 영화 리뷰 분석 본문
리뷰 긍부정 분석
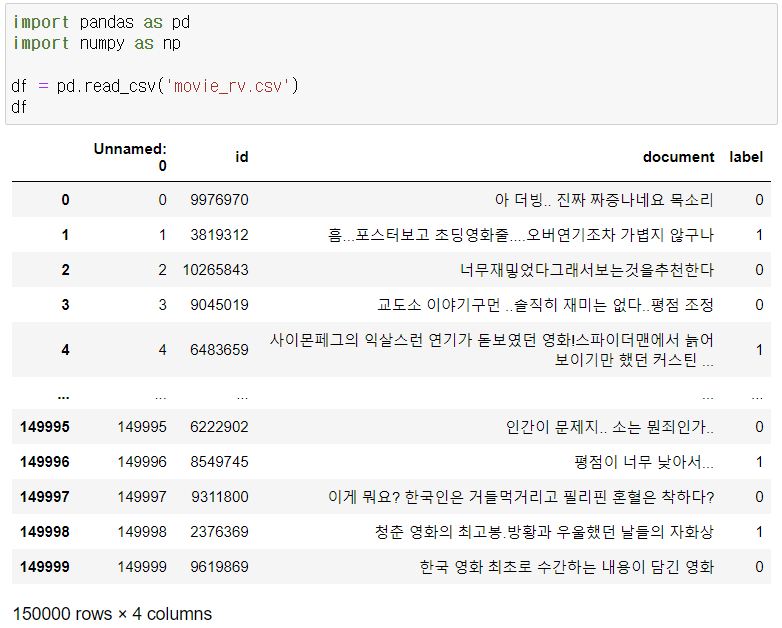
1. 리뷰 길이 컬럼 추가


2. 길이별 리뷰 긍부적 분석
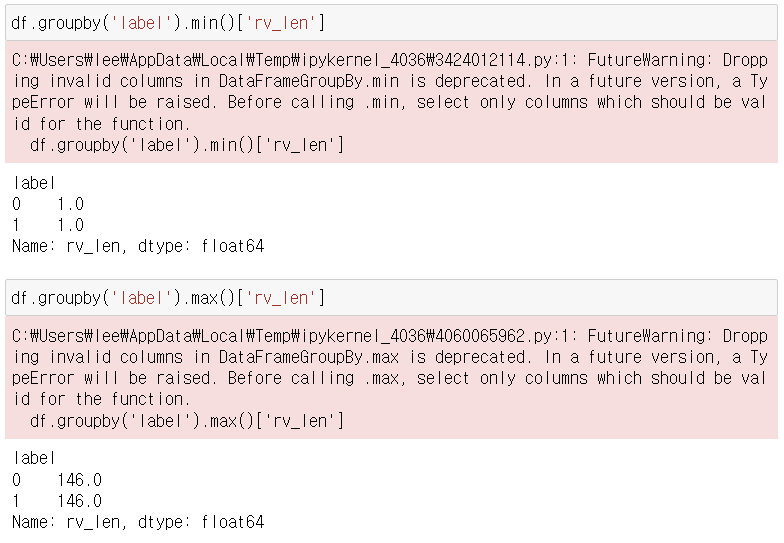
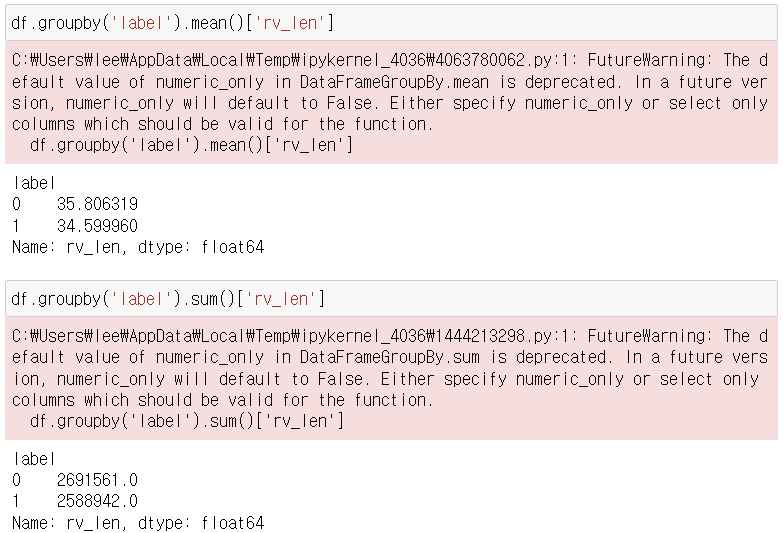

- 수치만으로는 긍부정 리뷰 길이가 유사한 것으로 판단됨.
3. 긍부정 분리 분석
- 긍부정별로 빈도수가 높은 단어 확인.
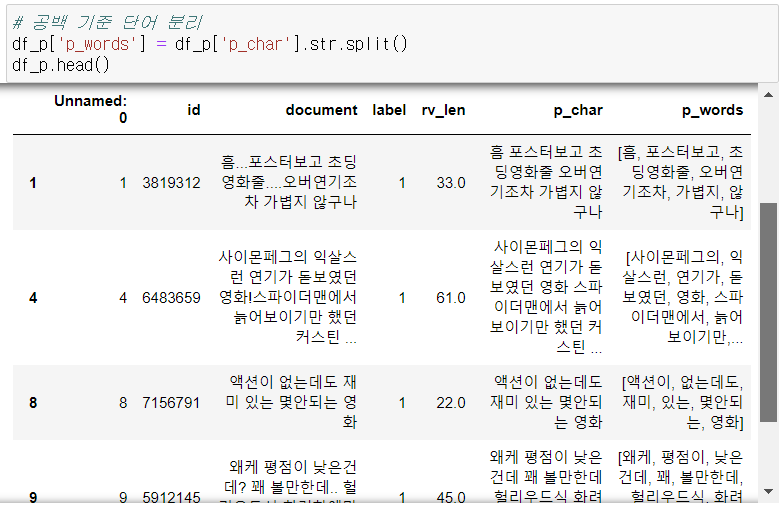
3-1. 긍정 리뷰 전처리
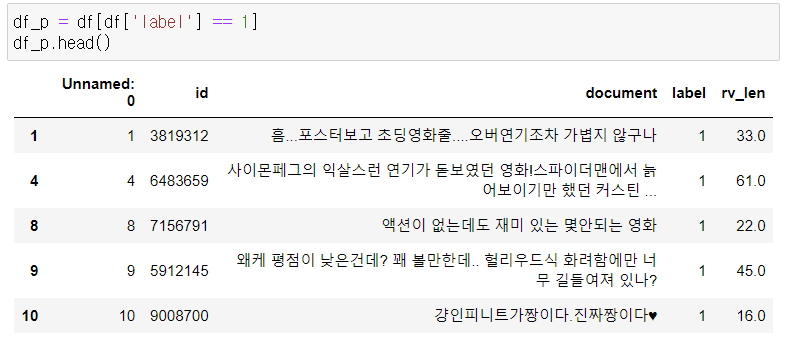





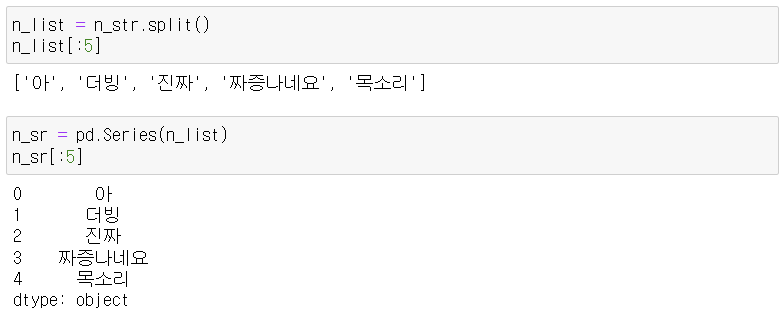
3-2. 부정 리뷰 전처리




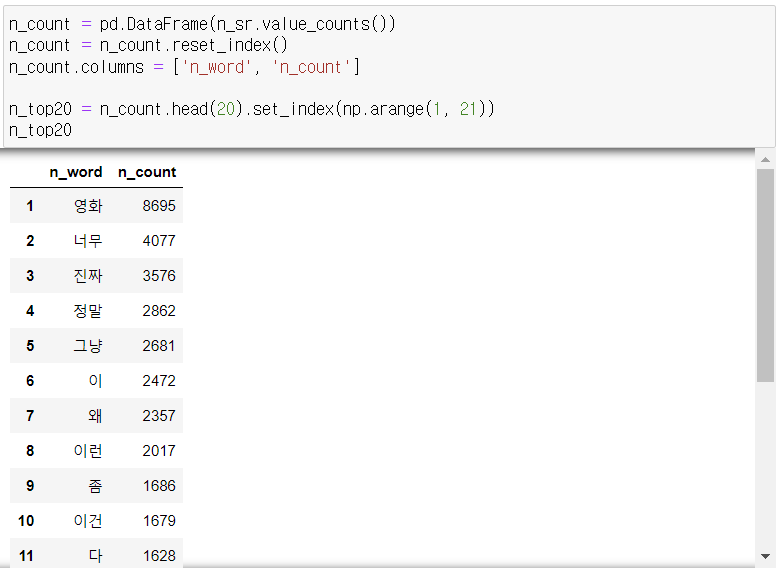
3-3. 종합 결론

- 긍정 리뷰에서 빈도가 높은 상위 키워드는 '최고의', '최고', '잘' 등이 있고,
- 부정 리뷰에서 빈도가 높은 상위 키워드는 '쓰레기' 등이 있다.
- 영화, 영화를, 이런 등 긍부정에 중복되는 의미없는 값을 제외하고 재분석 진행한다.
4. 중복 단어 제외 후 분석


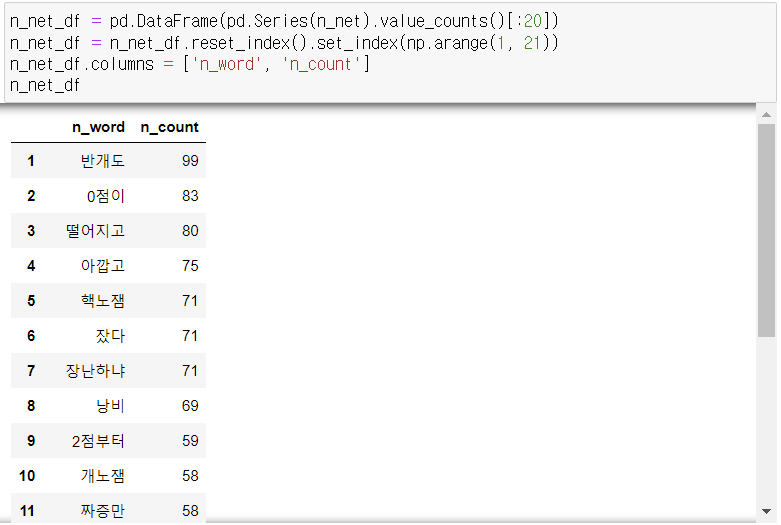
4-1. 중복 제거 종합 결론

- 차집합으로 중복 제외 추출하니 순서가 섞이고, value_counts() 결과가 정확히 나오지 않아 판단하기 어려웠음.
- for문을 이용하여 분석한 결과 정상적으로 산출되었음.
- 긍정 리뷰에는 '재미있었다', '감동이다' 등이 상위권에 자주 나타나며, 부정 리뷰에는 '재미없었다', '별로' 등의 평이 자주 나타남.
5. 불용어, 초성 제거 후 분석
- 불용어 리스트를 생성하고 불용어 제외 단어들로 분석하는 방법.




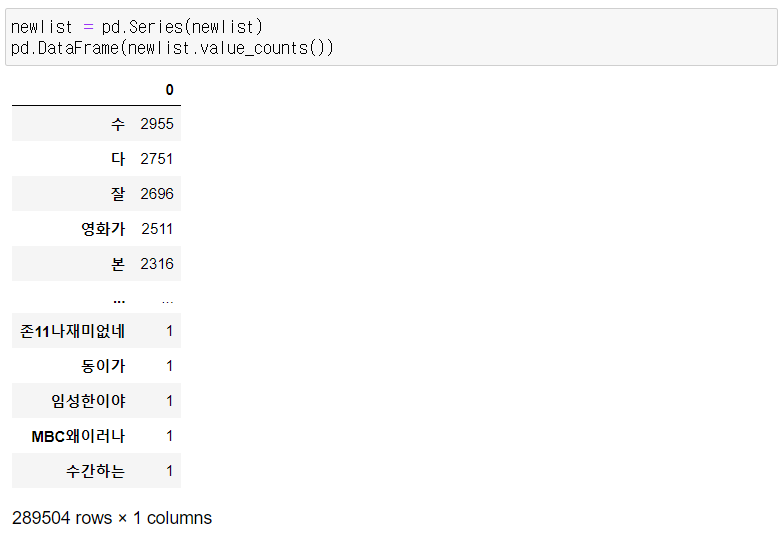
- 불용어를 전부 제거하지 못하면 정확한 결과가 추출되지 않으므로 두 리스트를 비교해 중복 단어를 제거하는 것이 더 효율적임.
'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 13주차 필수 과제 2 - konlpy로 영화 리뷰 분석 (0) | 2024.02.01 |
|---|---|
| [BDA 데분기] 13주차 - 텍스트 전처리, 토큰화, 태깅 (1) | 2024.02.01 |
| [BDA 데분기] 12주차 필수 과제 1 - 문자열 관련 함수 총 정리 (1) | 2024.02.01 |
| [BDA 데분기] 12주차 - 문자열 관련 함수 (0) | 2024.01.31 |
| [BDA 데분기] 11주차 - 데이터 전처리 (1) | 2024.01.31 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



