
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- matplotlib
- DataFrame
- 결측치대체
- koNLPy
- MSE
- value_counts
- Seaborn
- SimpleImputer
- KoNLP
- 불용어
- subplots
- BDA
- 대치법
- interpolate
- 전처리
- 이상치
- Python
- stopwords
- 누락값
- sklearn
- Boxplot
- 선형보간
- 파이썬
- IterativeImputer
- 결측치
- 데이터프레임
- 보간법
- join
- Outlier
- countplot
Archives
- Today
- Total
ACAIT
[BDA 데분기] 13주차 - 텍스트 전처리, 토큰화, 태깅 본문
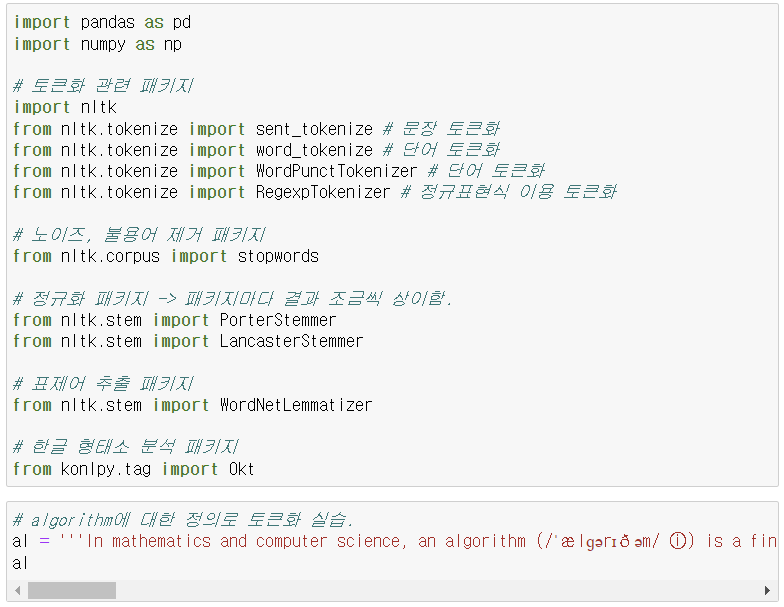
텍스트 전처리에 대한 내용을 정리해 보겠습니다.
텍스트 전처리
- 특수문자, 공백 제거 등의 정제 작업 이후 한글과 영어에 따라 전처리 작업 진행.
0. 전처리 종류
- 토큰화(Tokenization): 주어진 텍스트 잔위를 토큰을 나누는 작업.
- ex) 나는 밥을 먹었다 -> 나는 / 밥을 / 먹었다
- 문장 토큰화
- 단어 토큰화: 일반적인 토큰화 작업
- 단어보다 더 작은 형태로 토큰화 가능: 나 / 는
- 정규화: go, goes 등 주어에 따라 달라지는 의미가 비슷한 단어들을 하나로 정규화.
- 어간 추출, 표제어 추출
- 품사 태깅: 명사나 대명사, 형용사 등으로 태깅하여 원하는 분석 요구에 따라 사용.

1. 문장 토큰화
1-1. sent_tokenize(data)
- 온점 기준으로 한 문장씩 토큰화 진행.

2. 단어 토큰화
2-1. word_tokenize(data)
- 단어와 특수문자 모두 토큰화 처리됨.

2-2. WordPunctTokenizer().tokenize(data)
- 토큰화 결과 대체로 위와 유사하나 특수문자 등에서 상이함.
- 예를 들어 word_tokenize는 '를 /'라고 표현, WordPunctToknizer는 '라고 표현.

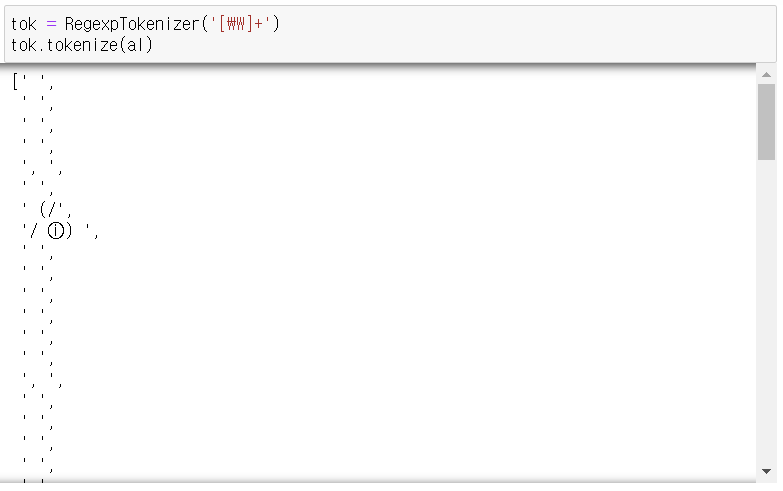
2-3. RegexpTokenizer(정규표현식).tokenize(data)
- 정규표현식으로 토큰화.
- 제시한 정규 표현식에 해당하는 단어 단위로 토큰화 진행.

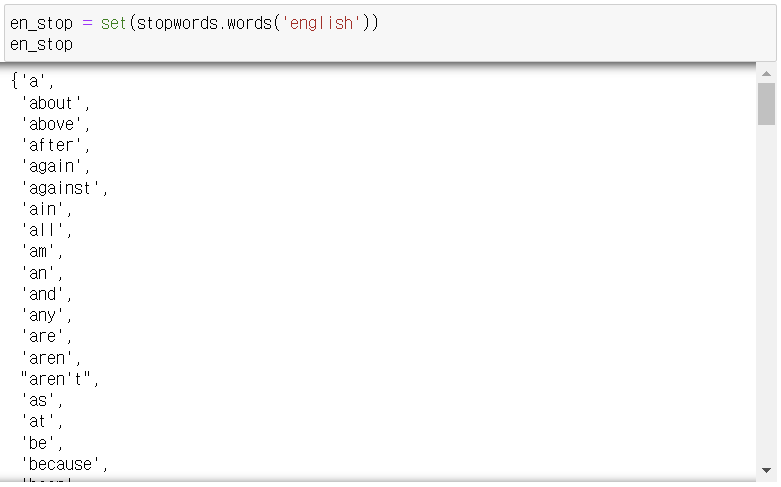
2-4. stopwords.words('language')
- 불용어 리스트를 불러와서 해당 리스트에 없는 단어만 추출하여 반환.



- 벡터화, 임베딩 후 자연어 처리할 때 단어 하나하나가 컬럼이 됨.
- 필요없는 걸 최대한 줄여야 차원이 축소됨. 단어가 많으면 차원이 늘어남.
- ex) 데이터가 다 0이 되는 희소성 문제 또는 계산 시 복잡해짐.
- ex) 또는 단어 추론 과정도 복잡.
3. 정규화 작업
- 어간(stem): 변하지 않는 부분.
- 어간을 추출한다는 개념으로 이해.
3-1. Poterstemmer(): 포터 스테머
- 패키지 선언 변수.stem('단어')

3-2. LancasterStemmer(): 랭카스터 스테마
- 결과는 패키지마다 상이할 수 있음. 사용법은 동일.
- 분석 방향에 맞춰서 어떤 패키지가 적합한지 판단 필요.

4. 표제어 추출
4-1. WordNetLemmatizer(), lemmatize(단어)
- 주어진 단어를 기본형으로 변환하는 것.
- 정규화와 유사해 보이나 데이터에 따라 정규화와 다른 것을 파악할 수 있음.

5. 품사 태깅
5-1. pos_tag(리스트)
- 품사를 태깅 -> 본래 의미를 사라지지 않게 의미있는 형태소로 만드는 것.
- 명사, 대명사, 동사, 형용사, 부사, 조사 등 공통된 성질을 지닌 낱말을 모아 두기 위한 작업.


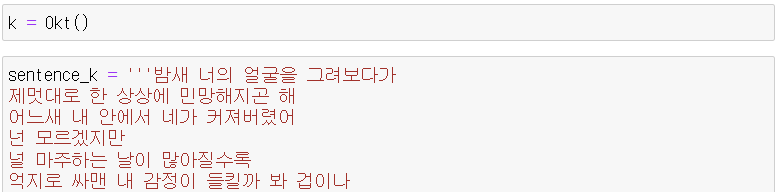
6. 한글 형태소 분석
6-1. Okt 선언 변수.기본 문법(data)
- konlpy.tag의 Okt를 이용한 분석 방법.
- Okt의 기본 문법
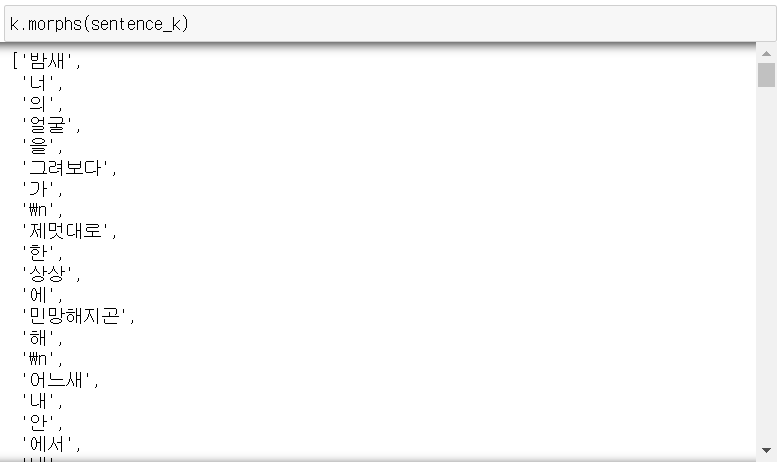
- morphs(phrase): 주어진 텍스트를 형태소 단위 분리.
- nouns(phrase): 주어진 텍스트를 형태소 단위로 분리해서 명사만 반환.
- pos(phrase): 주어진 텍스트를 형태소 단위로 분리해서 동사만 반환.



'학회 활동 > BDA 7기(데이터 분석 기초반)' 카테고리의 다른 글
| [BDA 데분기] 13주차 필수 과제 2 - konlpy로 영화 리뷰 분석 (0) | 2024.02.01 |
|---|---|
| [BDA 데분기] 12주차 필수 과제 2 - 영화 리뷰 분석 (0) | 2024.02.01 |
| [BDA 데분기] 12주차 필수 과제 1 - 문자열 관련 함수 총 정리 (1) | 2024.02.01 |
| [BDA 데분기] 12주차 - 문자열 관련 함수 (0) | 2024.01.31 |
| [BDA 데분기] 11주차 - 데이터 전처리 (1) | 2024.01.31 |
'학회 활동/BDA 7기(데이터 분석 기초반)' Related Articles
more



